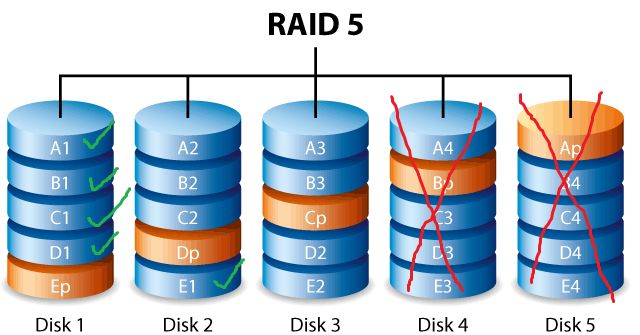
RAID (Redundant Array of Independent Disks) is a data storage technology that combines multiple disk drive components into a logical unit. RAID 5 is a commonly used RAID level that provides data redundancy by striping data across all the disks in the array and storing parity information with the data.
If one of the disks in a RAID 5 array fails, the array will continue to operate in a degraded state. The parity information allows the data from the failed disk to be recreated from the remaining disks. So even though one disk has failed, no data will be lost as long as the remaining disks stay healthy.
How Data is Stored in a RAID 5 Array
In a RAID 5 array, data is striped across all the disks, similar to RAID 0. However, unlike RAID 0, RAID 5 also stores parity information that is calculated based on the data blocks.
The parity information is distributed across all the disks and not stored on any one disk. For example, in a 3-disk RAID 5 array, Disk 1 may contain Parity 1, Disk 2 may contain Parity 2 and Disk 3 may contain Parity 3.
If any single disk fails, the parity blocks on the remaining disks can be used to reconstruct the data that was on the failed disk. This is how RAID 5 provides fault tolerance and protects against data loss.
RAID 5 Striping Example
| Disk 1 | Disk 2 | Disk 3 |
|---|---|---|
| Data A1 | Data B1 | Parity 1 |
| Data A2 | Parity 2 | Data C1 |
| Parity 3 | Data B2 | Data C2 |
As seen in the example, data blocks and parity blocks are distributed across the disks. The parity blocks are used to reconstruct data from a failed disk.
What Happens When a Disk Fails in RAID 5
When a single disk fails in a RAID 5 array, the array switches into a degraded mode. Thanks to the parity blocks, no data is lost when this happens. Here is what takes place:
1. The RAID controller detects the disk failure.
The RAID controller is monitoring the disks at all times. When it detects that a disk has become inaccessible due to failure, it marks the disk as failed in its metadata.
2. The array operates in degraded mode.
Even though one disk is inaccessible, the controller can still access data on the remaining disks. Using the parity blocks, any data that was on the failed disk can be recalculated. So the array continues to be fully functional, just without one disk worth of redundancy.
3. The failed disk is physically replaced.
The administrator replaces the failed hard disk with a new, identical one. This may require unmounting the array safely before swapping out the disk.
4. The data is rebuilt onto the new disk.
Once the new disk is installed, the controller starts rebuilding the data and parity onto it using the information from the surviving disks. All the while, the array remains online and accessible.
5. The rebuild completes and the array goes back to optimal state.
After all data is rebuilt, the array goes back to optimal mode with full redundancy. The new disk seamlessly takes the place of the old failed disk.
The Rebuild Process in Detail
When a disk rebuild takes place, the process involves:
- The RAID controller recalculating all the parity data using the information remaining on the surviving disks.
- The controller writing the reconstructed data from the failed disk onto the replacement disk.
- The parity being recalculated and written to the new disk as well.
This rebuild process takes some time depending on the size of the disks and the performance of the array. Larger capacity disks take longer.
During the rebuild, increased load is put on the surviving disks to access the data needed for the rebuild process. This is why it’s recommended to replace the failed disk as soon as possible, before a second disk also potentially fails during this period.
Prioritizing Rebuild Activity
Most RAID controllers allow you to set the priority of the rebuild activity. Setting it to a low priority will take longer but have minimal impact on performance. Setting to a high priority will finish faster but slow down other I/O activities.
Risks During Degraded Operation
When operating in degraded mode, the array is at risk if another disk fails before the rebuild completes.
If a second disk fails at this point, data loss will occur as the parity information is no longer sufficient to recreate all the data. This is why it’s crucial to replace the failed disk promptly to limit this window of vulnerability.
Disk Failure During Rebuild
In rare cases, the new replacement disk itself could fail while the rebuild is taking place. This puts the array at further risk.
If the controller detects this condition, it will abort the rebuild, mark the new disk as failed, and revert to running in degraded mode on the remaining disks.
The failed disk needs to be replaced again before restarting the rebuild. This reiterates the importance of using high quality, enterprise-grade drives designed for the rigors of RAID usage. Consumer-grade drives are more prone to fail, especially during rebuilds.
RAID 5 Rebuild Times
The amount of time a RAID 5 rebuild takes depends on several factors:
- The storage capacity of the disks in the array.
- The number of disks in the set.
- The performance of the drives and controller.
- The priority given to the rebuild operation.
As a general guideline:
| RAID 5 Disk Size | Average Rebuild Time |
|---|---|
| 1 TB | 2-5 hours |
| 2 TB | 4-10 hours |
| 4 TB | 8-20 hours |
| 6 TB | 12-30 hours |
| 8 TB | 16-40 hours |
The larger the disks, the longer the rebuild takes. Also, more disks in the array means more data to reconstruct.
Minimizing Rebuild Time
Some ways to minimize rebuild times include:
- Use higher performing enterprise-level drives.
- Use smaller capacity disks if possible.
- Limit the array size to 5-8 drives.
- Set the rebuild priority to high.
- Don’t tax the array with other I/O during rebuilds.
Also ensure proper cooling and adequate power is provided to the array during this intensive process.
What Happens if Multiple Disks Fail?
RAID 5 can only tolerate a single disk failure without data loss. If multiple disks in the array fail, complete data loss will occur as the parity information is no longer enough to recreate the missing data.
For example, if two disks fail at the same time, the RAID 5 array will crash and all data will be lost. The array requires all disks but one to be online to function.
This is why large RAID 5 arrays are particularly vulnerable to multiple disk failures. The likelihood of a second disk failing during rebuild increases as more disks are added.
RAID 6 for Dual Disk Fault Tolerance
For better protection against multiple disk failures, consider using RAID 6 instead of RAID 5 for arrays with 6 or more disks.
RAID 6 can handle up to two failed drives by using a second set of parity data, sometimes referred to as double parity. This provides an added layer of redundancy.
However, RAID 6 write performance is slower than RAID 5 due to the extra parity calculations required. Capacity efficiency also drops as more space is needed for the second parity drive.
Recovering Deleted Data from RAID 5
If files are accidentally deleted from a RAID 5 array, there are recovery methods that may be able to get the data back:
- Restore from backup: If proper backups exist, the fastest way to restore deleted data is to recover files from the backup.
- File recovery software: If no backup exists, run data recovery software against the array. This scans the drives and attempts to recover deleted files.
- File system logs: The logs may have information about the deleted files that recovery software can use.
- Drive imaging: A complete disk image can be taken of the array to safely recover files forensically.
However, the longer a RAID 5 array runs in degraded mode, the lower the chances of file recovery, as data gets overwritten over time.
Best Practices for RAID 5 Availability
To maximize availability in the event of drive failures, it’s recommended to follow these RAID 5 best practices:
- Use enterprise-class drives designed for RAID environments.
- Limit array size based on acceptable rebuild times.
- Monitor drive health proactively with smart monitoring tools.
- Set disk failure alerts and long rebuild time alerts.
- Keep spare drives ready for prompt replacement.
- Back up the array routinely for added protection.
Following redundancies best practices helps avoid prolonged degraded operation should disks begin failing in the array.
Conclusion
RAID 5 provides fault tolerance through distributed parity, enabling recovery from a single disk failure. When a disk fails, the array enters degraded mode and rebuilds the data onto a replacement disk using the parity blocks on the surviving disks.
To limit risk, failed disks must be replaced promptly, and arrays sized reasonably based on the resulting rebuild times. Larger arrays are more prone to multiple disk failures, so dual parity RAID 6 should be considered instead for these deployments.