What is RAID 5?
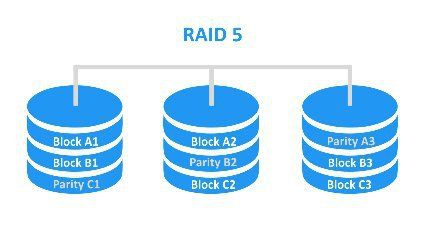
RAID 5 (Redundant Array of Independent Disks Mode 5) is a popular disk or solid state drive (SSD) subsystem that increases safety by computing parity data and increasing performance by striping data across drives. Parity data is additional information that is calculated and written across the drives that allows the array to recover data if one of the drives fails. According to this article, “RAID 5 requires at least three disks, but it is often recommended to use five or more disks for performance reasons.”
The key aspects of how RAID 5 works are:
- Data is striped across all the drives in the array, similar to RAID 0.
- Parity data is calculated and written across the drives along with the striped data.
- If a single drive fails, the parity data can be used to reconstruct the lost data from that drive.
- RAID 5 provides a good balance of performance and redundancy for most applications.
Compared to RAID 1 mirroring, RAID 5 is more efficient in its use of drive capacity while still providing redundancy. By distributing parity data across drives, RAID 5 eliminates the bottleneck of a dedicated parity drive. This makes RAID 5 a popular choice for redundancy and performance.
How Data is Stored in RAID 5
RAID 5 stores data using a method called striping with distributed parity. This means the data is divided into stripes that are spread out across all the drives in the array, providing better performance compared to a single drive (TechTarget, 2022).
Along with striping, RAID 5 also uses parity information for redundancy. Parity is calculated using an XOR operation on the data in each stripe. The resulting parity information is also striped and distributed evenly across all the drives, unlike RAID 4 which stores parity on a dedicated drive (Open-E, 2022). By distributing parity, RAID 5 avoids potential bottlenecks.
So in summary, RAID 5 stripes data and parity evenly across all disks. This provides faster reads and writes compared to a single disk, while also providing fault tolerance through the distributed parity stripe.
Drive Failure in RAID 5
In a RAID 5 array, data and parity information are striped across all the drives. If one drive fails, the array is still able to operate using the parity data to reconstruct the missing information 1. This provides fault tolerance and allows a RAID 5 array to withstand a single drive failure without data loss.
When a drive fails in a RAID 5 array, the disk controller detects it as a missing drive and the array goes into a degraded state. At this point, data can still be accessed but without redundancy. The array is operating without parity information and remains vulnerable to a second disk failure 2.
To regain full redundancy and protection, the failed drive must be replaced and the RAID rebuilt with the new replacement drive. The controller uses the parity data to reconstruct the data that was on the failed drive and write it to the replacement drive. This rebuild process restores redundancy and fault tolerance to the RAID 5 array.
Automatic Rebuilding in RAID 5
RAID 5 is designed with automatic rebuilding capabilities to protect against drive failures. It uses a dedicated parity drive to store error correction data calculated from the data blocks across the RAID array.
When a drive in a RAID 5 array fails, the RAID controller will detect the drive failure and automatically initiate a rebuild using the parity data. The parity data allows the RAID controller to recalculate the missing data from the failed drive and reconstruct that data onto a replacement drive.
The automatic rebuilding process works as follows:
- The RAID controller detects the failed drive.
- A spare or replacement drive is inserted into the RAID array.
- The RAID controller calculates the data that was on the failed drive using parity data from the dedicated parity drive.
- The reconstructed data is written to the replacement drive.
This rebuild process occurs in the background with minimal impact to system performance. The RAID 5 array remains operational during the rebuild, providing fault tolerance. Once rebuilding is complete, the RAID 5 array returns to optimal redundancy.
The key advantage of RAID 5’s auto-rebuild capability is avoiding downtime and data loss when a single drive fails. The dedicated parity drive enables the RAID array to self-heal with no manual intervention required.
Rebuilding Process
The rebuilding process in RAID 5 involves reading all the data from the remaining disks and writing it to the replacement disk. This is done stripe-by-stripe, with each stripe consisting of multiple blocks of data and parity information across the array.
The time required for rebuilding depends on the size of the disks and the number of disks in the array. For example, rebuilding a 6TB RAID 5 array with 5 disks could take 6-12 hours. Larger arrays with more disks will take proportionally longer.
According to HP, the rebuild process can impact performance of the array, reducing overall throughput by 50-75% [1]. This is because the rebuild competes with normal I/O requests for disk access. The impact will be most noticeable on write-heavy workloads.
To minimize impact, the rebuild priority can be lowered on some RAID controllers. Non-essential I/O workloads should be avoided during rebuild if possible.
Monitoring and Notifications
RAID 5 arrays continuously monitor the health status of all disks in the array. The RAID controller checks for signs of impending disk failure, like an increase in soft read errors. Most RAID controllers have built-in Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T.) to monitor disk health.
When the controller detects a critically failed disk, it will instantly send an alert and error message to notify the system administrator. Most RAID controllers allow configuring notifications through email, SMS, or system logging. Some monitoring software like Spiceworks also enable monitoring RAID status remotely.
Monitoring tools check disk health metrics like read/write errors, spin-up time and temperature. They send alerts when thresholds are crossed, indicating potential disk trouble. Regular monitoring helps detect problems early before multiple disk failures occur.
Best Practices
When using RAID 5, it’s important to follow best practices to ensure data integrity and improve rebuild times in the event of a drive failure. Here are some tips:
- Perform regular drive health checks and replace drives that are showing signs of failure before they completely fail. Monitoring drive SMART stats can help identify problem drives.
- Keep spare drives on hand that can be quickly swapped in in the event of a failure. Having spares ready reduces rebuild times.
- Use enterprise-grade drives designed for RAID environments. Consumer drives may not be reliable enough for RAID.
- Back up data regularly. Backups provide an additional layer of protection against data loss.
- Consider using RAID 6 instead of RAID 5 for better fault tolerance. RAID 6 can survive two drive failures.
- Monitor the RAID status closely. Many RAID controllers provide notifications for events like drives going critical.
Following best practices helps avoid complete RAID failures and minimize downtime when recovering from drive issues.
When Rebuilding Fails
There are a few scenarios where a RAID 5 rebuild can fail:
If there are bad sectors on the remaining disks that cannot be read, the rebuild will fail as the data cannot be reconstructed (RAID 5 Data Recovery). This is more common with older drives.
If a second drive fails during the rebuild process, the RAID will be unrecoverable without professional data recovery services (Raid 5 rebuild failure). The likelihood of a second failure increases with larger capacity drives.
Controller cache failure during rebuild can also lead to a failed rebuild. The controller plays a crucial role in managing the parity calculations (Re-Evaluating RAID-5 and RAID-6 for slower larger drives).
If the rebuild fails, the data will be inaccessible unless recovered by a professional RAID recovery service. Some options include:
- Replacing failed components and retrying rebuild
- Inserting drives in another system to read data
- Using advanced recovery tools to reconstruct RAID
To avoid rebuild failures, it’s recommended to use enterprise-grade components and monitor drive health.
Alternatives to RAID 5
There are several alternatives to RAID 5 that provide greater redundancy and protection against multiple drive failures.
RAID 6
RAID 6 is considered an advancement over RAID 5. Like RAID 5, data and parity information are striped across all the drives. However, RAID 6 utilizes two independent distributed parity schemes instead of one. This means RAID 6 can sustain up to two concurrent disk failures without data loss (Shand, 2022).
The tradeoff is reduced overall array capacity and decreased performance compared to RAID 5. However, many consider the extra fault tolerance worth it for large, critical storage systems.
RAID 10
RAID 10 combines distributed data striping like in RAID 0 and disk mirroring like in RAID 1. Data is written across multiple disks in a stripe, then each stripe is mirrored onto another set of disks (TechTarget, 2022).
This provides high throughput and redundancy. RAID 10 can withstand multiple drive failures so long as no more than one drive fails per mirrored set. The downside is relatively low overall array capacity.
RAID 10 is considered preferable for high performance applications where redundancy is still important, like transactional databases.
Summary
In summary, RAID 5 automatically rebuilds failed drives in most situations to restore redundancy and prevent data loss. The rebuilding process uses parity data spread across the remaining disks to reconstruct the data that was on the failed drive. This happens transparently in the background after a failure is detected. The length of time it takes to rebuild depends on the size of the drives and the controller’s processing power. It’s important to monitor the rebuilding process and have hot spares available in case another drive fails during the rebuild. Regular backups are still essential in case multiple drive failures exceed the fault tolerance of RAID 5. While automatic rebuilding is a key benefit of RAID 5, there are also alternatives like RAID 6 or RAID 10 that provide additional redundancy and may be preferable in some situations.
The key points around RAID 5 automatic rebuilding are:
- RAID 5 uses distributed parity to restore data after a single drive failure.
- The rebuilding process happens automatically after a failed drive is detected.
- Rebuilding reads parity data from the remaining disks to reconstruct the lost data.
- The rebuild time depends on the size of the drives and controller performance.
- It’s crucial to monitor rebuild progress and have hot spares available.
- Backups are still needed in case multiple drives fail.
- Alternatives like RAID 6 and 10 offer more redundancy.