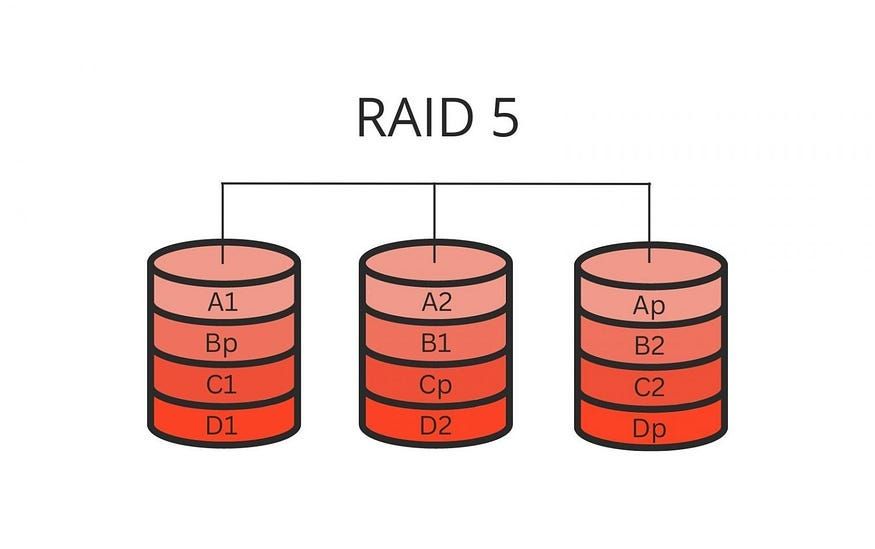
What is RAID 5?
RAID 5 is a storage technology that combines multiple hard disk drives into one large logical drive for the purposes of data redundancy and performance. It utilizes distributed parity, meaning the parity information is distributed across all the drives.
This allows the array to continue operating even if one of the drives fails. The key benefit of RAID 5 is that it provides redundancy and fault tolerance without requiring as much unused capacity as mirroring (RAID 1) requires.
How does parity work in RAID 5?
Parity information is calculated using an XOR operation across the data on the member disks. This parity information can be used to reconstruct data if one of the drives fails.
For example, given Disks A, B, and C, the parity would be calculated as:
Parity = A XOR B XOR C
If Disk A failed, the data could be reconstructed as:
A = B XOR C XOR Parity
This provides protection against a single disk failure, as the data on the failed drive can be recreated from the data and parity information on the remaining drives.
RAID 5 stripe size and block size
When configuring a RAID 5 array, two important factors are the stripe size and the block size.
The stripe size refers to the amount of data written to each disk before moving to the next disk. For example, with a 3-disk RAID 5 array and a stripe size of 64KB, the first 64KB of data would be written to Disk 1, the next 64KB to Disk 2, the next to Disk 3, and the next back to Disk 1 again.
The block size refers to the smallest amount of space allocated on the drives to hold data. Each block stores either data or parity information. Typical block sizes are 512 bytes, 1024 bytes, 2048 bytes, or 4096 bytes.
The choice of stripe size and block size can impact performance and efficiency, so it’s important to take the application workload into account when configuring the array.
Calculating RAID 5 total space
The total usable space in a RAID 5 array depends on the number of disks, the size of the disks, and the stripe size. Here are two common ways to calculate the total space:
Method 1 – Based on member disk size
Total space = (Number of disks – 1) x Size of smallest disk
For example, with 3 x 1TB disks, the total space would be:
= (3 – 1) x 1TB
= 2TB
One disk worth of space is lost to parity, so a 3-disk RAID 5 array with 1TB drives would yield 2TB total space.
Method 2 – Based on stripe size
Total space = (Sum of all disk sizes) – (Size of one member disk)
For example, with 3 x 1TB disks and a 64KB stripe size:
– Sum of all disk sizes = 3TB
– Size of one member disk = 1TB
– Total space = 3TB – 1TB = 2TB
This method accounts for the fact that not all the space on the disks is available due to the chunking from the stripe size.
Impact of different stripe sizes
The choice of stripe size impacts the overall storage efficiency of the array. Let’s look at an example:
Example:
– 3 x 500GB disks
– Block size of 512 bytes
With 64KB stripe size:
– Each stripe = 64KB
– With 512 byte blocks, each stripe = 128 blocks
– 2 blocks per stripe are parity blocks
– So each stripe stores 126 data blocks
– With 64KB stripes, there are 500GB / 64KB = 8,000,000 stripes
– So total data blocks stored = 8,000,000 * 126 = 1,008,000,000
– Each block is 512 bytes, so 1,008,000,000 blocks * 512 bytes per block = ~476GB per disk
– Total capacity = (3 disks – 1) * 476GB = 952GB
With 256KB stripe size:
– Each stripe = 256KB
– Each stripe = 512 blocks
– 2 are parity, so 510 are data
– Number of stripes = 500GB / 256KB = 2,000,000
– So total data blocks = 2,000,000 * 510 = 1,020,000,000
– Total capacity = (3 disks – 1) * 500GB = 1TB
So a larger stripe size is more storage efficient but can impact performance. A smaller stripe size reads and writes from disks more frequently.
RAID 5 disk failure scenarios
RAID 5 can withstand a single disk failure without data loss. Here are the failure scenarios:
Single disk failure
If a single disk fails, the parity blocks on the remaining drives can be used to recalculate the missing data. Performance is degraded in this scenario but all data remains accessible.
The failed drive should be replaced as soon as possible. Once replaced, the RAID array can rebuild the data on the new disk using the parity information.
Second disk failure
If a second disk fails before the first failed drive has been replaced and rebuilt, this would result in complete data loss and failure of the RAID 5 array. The parity information can only recover a single drive failure.
To protect against this scenario, it’s critical to replace failed drives quickly. Many RAID controllers also support hot spares which can automatically rebuild data if a second disk fails.
Rebuilding after disk failure
When replacing a failed drive, the new disk must be rebuilt to restore redundancy. This rebuild process reads all data blocks from the surviving disks and calculates the missing data to restore on the new disk.
This process is resource intensive and can take hours or days with large high capacity drives or arrays. During the rebuild, there is no protection against an additional disk failure.
RAID 5 performance
RAID 5 performance characteristics include:
– Read performance – Reads can be distributed across multiple disks in parallel, so RAID 5 can provide improved read performance compared to a single disk.
– Write performance – Writes require parity calculations which can impact write speeds. However, writes are also distributed which can provide a performance improvement over a single disk.
– Capacity utilization – Given N disks, RAID 5 storage efficiency is N-1, meaning capacity is (N-1)/N times the total disk size. So a 3-disk RAID 5 uses 67% of total capacity.
– Rebuild performance – Rebuilding a failed drive requires reading all data from all drives and recalculating parity. This significantly slows the array while rebuilding.
Overall, RAID 5 provides good performance for general workloads while also providing fault tolerance. Performance critical applications may prefer RAID 10 which stripes and mirrors data.
Choosing stripe size and block size
Some best practices for choosing RAID 5 stripe size and block size:
– Match the stripe size to your I/O workload patterns. Applications with large sequential transfers favor larger stripes while transactional workloads prefer smaller stripes.
– Keep the stripe size a multiple of the block size for optimal storage utilization.
– Use a smaller block size for RAID arrays with many small writes to avoid wasted space.
– For read-intensive workloads, use a larger stripe size to allow more drives to operate in parallel.
– For write-intensive loads, smaller stripes can provide better distribution of writes across the disks.
– Test performance with representative workloads and different stripe sizes to determine optimal values.
There are always tradeoffs between performance, storage efficiency, and rebuild times, so benchmarking your particular workload is key.
When to choose RAID 5
RAID 5 can be a good option in the following cases:
– Environment requires redundancy and can tolerate the write performance impact. Database servers are commonly deployed in RAID 5.
– Budget constraints limit the amount of capacity that can be spent on redundancy/availability. RAID 5 provides good utilization compared to RAID 1 mirroring.
– Rebuild time with modern large-capacity SATA drives is a concern. RAID 6 can require long rebuild times when drives fail.
– Workload is primarily read operations. The redundant reads of RAID 5 can provide a performance boost.
– Cost per GB is critical. The N-1 capacity usage of RAID 5 provides good utilization.
– Workload is not extremely write performance sensitive. RAID 10 may be preferred for high performance requirements.
When to avoid RAID 5
RAID 5 may not be the best choice in these cases:
– Rebuild time is critical – With large drives, RAID 6 or RAID 10 rebuilds faster.
– Performance requirements are highly write intensive. The write penalty of RAID 5 parity may not provide acceptable speeds.
– Maximum redundancy is needed. RAID 6 provides additional fault tolerance.
– Cost is less of a concern than performance and redundancy. RAID 10 can provide faster speeds.
– Data storage requires the highest integrity. The risk of unrecoverable read errors during RAID 5 rebuilds is a concern.
Alternatives to RAID 5
Some alternatives to consider instead of RAID 5:
– RAID 10 – Disk mirroring and striping. Provides high performance but 50% storage utilization.
– RAID 6 – Double distributed parity providing two disk failure tolerance.
– RAID 50/60 – Nested RAID levels combining multiple RAID 5 arrays into a RAID 0 stripe.
– ZFS/Btrfs RAIDZ – Software RAID that provides advanced checksums and scrubbing.
– Storage Spaces – Microsoft software RAID supporting mirroring and parity.
– UnRAID – Proprietary software RAID optimized for media storage.
– JBOD – Just a Bunch of Disks with no parity or redundancy. Maximizes capacity.
The choice depends on the specific requirements including performance, availability, and cost.
Conclusion
Calculating the capacity of a RAID 5 array requires accounting for the distributed parity and chosen stripe size. While RAID 5 does come with a write penalty, it can provide good performance for applications requiring redundancy on a budget.
When selecting stripe size and block size, benchmark representative workloads to select optimal values. As drive sizes increase, consider alternatives like RAID 6 or RAID 10 for very large arrays.
For general use cases requiring fault tolerance, RAID 5 remains a tried and true option that maximizes storage utilization. Carefully evaluate workload requirements and test configurations to select if RAID 5 is the right choice.