RAID 5 is a popular RAID (Redundant Array of Independent Disks) configuration that provides fault tolerance by using distributed parity. This means that the data and parity information are distributed across all the disks in the array. If one disk fails, the parity information can be used to reconstruct the data that was on the failed drive. But how much data is actually at risk if a disk fails in a RAID 5 array?
What is RAID 5?
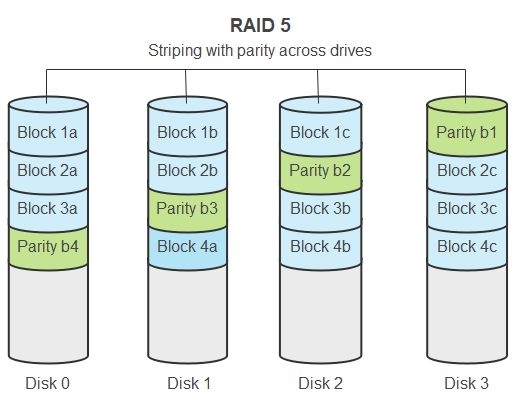
RAID 5 requires a minimum of 3 disks. Data is striped across all the disks, similar to RAID 0. Unlike RAID 0 however, RAID 5 also reserves one disk’s worth of space for parity information. This parity data is distributed across all the disks and can be used to reconstruct data in the event of a single disk failure.
For example, in a 3-disk RAID 5 array, Disks 1 and 2 might contain file data A and B respectively. Disk 3 would contain parity data A+B. If Disk 2 were to fail, the RAID controller could use the data on Disk 1 and the parity on Disk 3 to reconstruct the data that was on Disk 2.
How much data is lost if a disk fails?
When a single disk fails in a RAID 5 array, no data is actually lost. The parity information is used to reconstruct the data that was on the failed drive and write it to a replacement drive. Once rebuilt, the array is restored to full redundancy.
However, while the array is in a degraded state, there is an increased risk of data loss. If a second disk were to fail before the rebuild completes, data loss could occur. The amount of data at risk depends on the RAID 5 geometry:
- In a 3-disk RAID 5, the entire array capacity is at risk during a degraded rebuild.
- In a 4-disk RAID 5, 50% of the array capacity is at risk.
- In a 5-disk RAID 5, 33% of the array capacity is at risk.
- In a 6-disk RAID 5, 28% of the array capacity is at risk.
The more disks in the RAID 5 array, the less data is at risk during a degraded rebuild. But regardless, a second disk failure during this period could be catastrophic.
Why data loss occurs
Data loss occurs when a second disk fails before the RAID 5 array can rebuild itself. Remember that the parity information is also distributed across the disks. So if a second disk fails that contains parity info for data on the failed drive, that data cannot be reconstructed.
For example, consider a 3-disk RAID 5 where Disk 1 fails. While rebuilding Disk 1, if Disk 2 also fails, all data will be lost. This is because the parity data on Disk 3 is meaningless without the data on Disks 1 and 2 to reconstruct from.
Probability of data loss
The probability of a second disk failing during a RAID 5 rebuild depends on the Mean Time Between Failures (MTBF) of the disks. MTBF is a manufacturer’s estimate of how long a drive should operate before failing.
For example, if the MTBF is 1,000,000 hours, we can calculate the probability of failure in a 3-disk RAID 5 as follows:
- Disk 1 initial failure – probability is 1/MTBF = 1/1,000,000 = 0.000001 = 0.0001%
- Disk 2 failure during rebuild – probability is 1/MTBF = 1/1,000,000 = 0.000001 = 0.0001%
- Probability of both happening: 0.0001% * 0.0001% = 0.0000000001%
While the probability is very low, the consequence is complete data loss. As the array size grows, the probability decreases further but is never zero.
Factors that affect failure rates
Several factors can affect disk failure rates and increase the likelihood of a second failure occurring during a degraded rebuild:
- Disk vintage – Older disks are more prone to failure than newer ones.
- Temperature – Higher temperatures increase failure rates.
- Workload – Heavier disk workloads increase failure rates.
- Rebuild time – The longer a rebuild takes, the higher the risk.
Using enterprise-class drives rather than consumer-grade ones, monitoring drive temperatures, balancing workloads, and using faster drives to reduce rebuild times can all help minimize the risk.
Reconstructing data after failure
When a disk fails in RAID 5, the volume will switch into a degraded mode and the RAID controller will start a rebuild process in the background. Here is what happens:
- The failed drive is removed from the array.
- A replacement drive is inserted.
- The controller begins reading all data blocks and parity from the surviving disks.
- The missing data is calculated from the parity information.
- The reconstructed data is written to the replacement drive.
This rebuild process restores redundancy to the array. The larger the disks, the longer the rebuild takes. During this time, the array is vulnerable to a second failure.
Minimizing downtime and risk
There are several best practices to minimize downtime and risk of data loss during RAID 5 rebuilds:
- Use hot spare drives that can immediately start rebuilding.
- Use hot-swap drive bays for easy replacement.
- Use smaller drive sizes to reduce rebuild times.
- Balance workloads evenly across drives.
- Monitor drive temperatures and health.
- Schedule proactive drive replacements.
What happens if two disks fail?
If two disks fail simultaneously in a RAID 5 array, complete data loss will occur. The volume will be totally unusable until those failed drives are replaced. However, only after replacing the failed drives can the administrator see how much data was lost.
If two disks fail sequentially before a rebuild finishes, a similar outcome occurs. The total amount of data loss will be equal to the sum of the capacities of the two failed drives.
For example, in a 3-disk RAID 5 with 1TB drives, if Disk 1 fails and then Disk 2 fails during rebuild, all 2TB of data will be lost. The array could be rebuilt after replacing the drives, but the original data cannot be recovered.
Recovering from two drive failures
If two disks fail in a RAID 5 array, the recovery process involves:
- Replacing both failed drives.
- Rebuilding the array from scratch.
- Restoring data from backups.
If the failures caused complete data loss, the only option is to restore from backups. This emphasizes the importance of maintaining recent backups for the ability to fully recover from a RAID 5 double-drive failure.
Triple-drive failure scenarios
In rare cases, it is also possible for three disks to fail in a RAID 5 array. Here are the possible scenarios:
- Three simultaneous failures – The RAID 5 array will be totally destroyed with 100% data loss. Only restoration from backup can help.
- Two failures, then third failure during rebuild – Same outcome as above. Total data loss with only backup restoration as an option.
- One failure, two failures during rebuild – Same outcome again. 100% data loss since two disks containing data are lost.
The scenarios illustrate that there is no way to recover from three disk failures in RAID 5 if the drives contain critical data. Backups are mandatory.
Maximizing RAID 5 availability
To maximize availability in RAID 5 arrays, administrators should:
- Use enterprise-class drives with high MTBF.
- Limit RAID 5 arrays to no more than 6-8 drives.
- Keep spare drives ready for immediate rebuilds.
- Schedule periodic drive replacements.
- Monitor drive health and temperatures.
- Balance workloads evenly.
- Use a battery-backed write cache.
- Use UPS/generators for power failure protection.
However, despite best efforts, RAID 5 arrays are always vulnerable to multiple drive failures. Regular backups are necessary as a last line of defense.
RAID 6 dual parity for added protection
For higher availability, RAID 6 arrays use double distributed parity instead of the single parity drive in RAID 5. This allows the array to withstand up to two disk failures.
In RAID 6, two sets of parity data are calculated using different mathematical formulas. This provides additional redundancy. Data can still be reconstructed if up to two disks fail simultaneously.
The trade-off is reduced usable capacity since two disks are needed for parity instead of one. But the extra protection against dual-drive failures makes RAID 6 a popular choice for mission-critical storage.
Advanced RAID protection levels
Beyond basic RAID levels, there are also advanced RAID implementations that use multiple parity drives to provide protection against even more disk failures:
- RAID 50 – Block-level striping like RAID 0 across RAID 5 groups. Can sustain multiple drive failures across groups.
- RAID 60 – Similar to RAID 50 but with RAID 6 groups for dual parity.
- RAID-DP – NetApp’s RAID Double Parity. Up to two disk or data path failures per RAID group.
- RAID 1E – Enhanced mirroring technique that uses three or more mirrored copies instead of two.
The advanced RAID options provide incremental improvements in availability and fault tolerance. But they also reduce usable capacity for parity purposes. The trade-offs need careful analysis when selecting a RAID level.
Disk failure statistics and trends
Looking at real-world disk failure statistics can provide insight into how often RAID 5 arrays might experience multiple drive failures. Backblaze is one provider that has published extensive data about drive reliability in their data centers. Here are some key stats:
- 1.5% – 3.5% annualized failure rate for consumer-grade drives
- 0.5% – 0.9% annualized failure rate for enterprise-class drives
- 60% of drives survive past 4 years
- 20% of drives survive past 6 years
- MTTF (mean time to failure) ranges from 2 – 6 years depending on quality
What this shows is that on average, consumer drives are 3-4 times more likely to fail in a given year compared to enterprise models. But even enterprise drives average around a 1% annual failure rate, so dual failures in a RAID 5 array are a real statistical possibility over time.
Failure rates also steadily increase as drives age, so the MTTF gives a false sense of security. Regular replacement of older drives helps mitigate higher failure rates later in the lifecycle.
Replacing RAID 5 with RAID 6 or 1E
Given the vulnerabilities in RAID 5, many organizations are migrating to RAID 6 to lower the risks. With its dual parity, RAID 6 offers much higher resilience against multiple failures. The trade-offs are complexity and reduced usable capacity.
For smaller storage environments where redundancy is critical, mirroring or RAID 1 configurations provide simpler redundancy. RAID 1E adds even more redundancy by using three full copies of data instead of two.
Virtualized storage environments also allow easier migration between RAID levels. Dynamic RAID conversion allows adjusting the RAID protection as needs change over time.
Using advanced file systems and backups
Beyond RAID, modern file systems like ZFS and ReFS also support redundancy and error checking features that enhance data integrity. Copy-on-write transactional models minimize corruption. Snapshots also provide recovery points.
These advanced file system technologies complement RAID and can detect data inconsistencies or administrator errors. But backups are still required for disaster recovery scenarios like prolonged power outages, flooding, fires or malware.
Software vs hardware RAID
Software RAID relies on the CPU for parity calculations and other RAID management functions. Hardware RAID offloads these tasks to a dedicated RAID controller card with battery-backed cache. The advantages of each are:
- Software RAID – No added hardware cost, fully customizable, portable between systems.
- Hardware RAID – Improved performance, dedicated processing power, additional cache, battery backup for cache data.
Hardware RAID delivers better performance and reliability. But software RAID is cheaper and offers more flexibility. The choice depends on budget and performance requirements.
RAID controller cache protection
RAID controller cards often contain a memory cache used to expedite writes. Without battery backup, this cache data can be lost on power failure. But many controllers have capacitor-based flash storage or NVDIMM to staging data.
Cache protection mechanisms ensure pending cache data gets flushed to disk in case of power loss. This helps prevent RAID corruption during unexpected reboots and outages.
Importance of monitoring RAID status
Actively monitoring RAID array health and drive status is critical to detect issues before dual failures occur. Most RAID controllers and server operating systems provide statistics on:
- Current drive state (online, failed, rebuilding)
- Drive temperatures and wear
- Bad blocks and pending sectors
- Background rebuild progress
- Current resync/rebuild rate
Monitoring tools like SNMP traps, dirpath watches and smartd can also provide alerts on RAID events and predictive drive failures.
Conclusion
RAID 5 provides solid protection against single drive failures. But during rebuild states, a significant portion of the array capacity is vulnerable to a second disk failure and potential data loss. To truly protect against dual-drive failures, upgrade to RAID 6 or higher mirrors.
No RAID level is immune to multiple failures however. So combine RAID with monitoring, hot spares, backups and advanced file systems. This defense-in-depth approach is essential for maximizing availability and minimizing RAID 5 data loss risks.