Amazon S3 (Simple Storage Service) is an object storage service offered by Amazon Web Services (AWS). Object storage like S3 stores data as objects in a flat structure unlike block storage which stores data in blocks within sectors and tracks. So Amazon S3 is considered object storage, not block storage.
What is object storage?
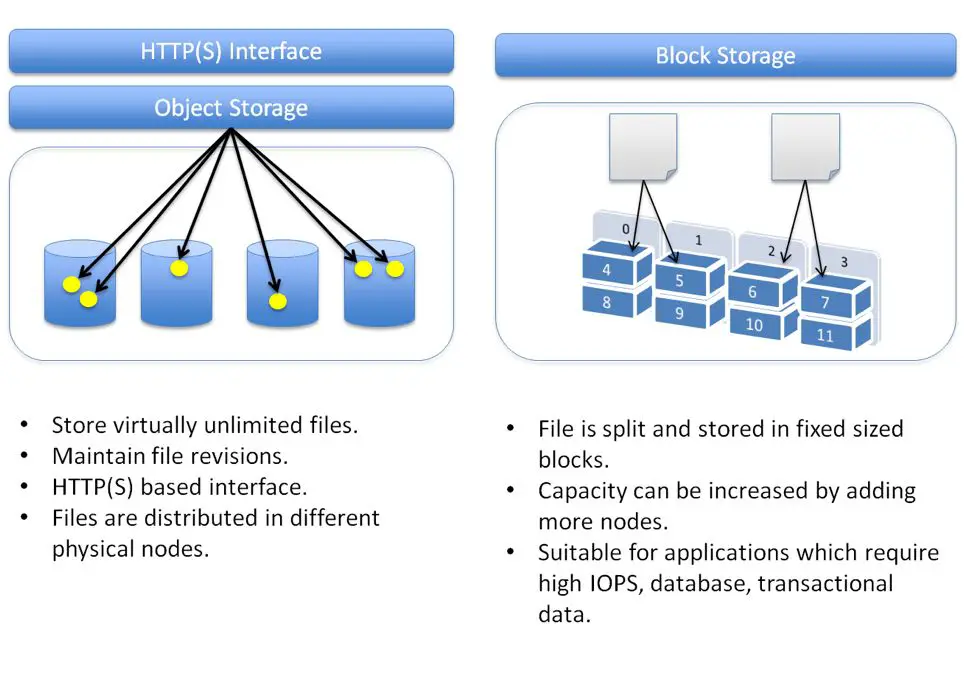
Object storage is a data storage architecture that manages data as objects, as opposed to other storage architectures like file systems which store data in a hierarchy, and block storage which stores data in blocks within sectors and tracks. Each object in object storage typically includes the data itself, a variable amount of metadata, and a globally unique identifier. Object storage stores the data objects in a flat address space unlike the hierarchical file system found on local disks.
The main characteristics of object storage are:
- Objects are stored in a flat address space instead of as files in folders/directories or blocks on a disk.
- Each object has a unique identifier for retrieval.
- Metadata attached to objects describes the data and allows for searchability.
- Designed for scale out over commodity hardware.
- Highly durable with data replication built in.
This architecture makes object storage ideal for storing large volumes of unstructured data like photos, videos, log files, backups, and more. It’s scalable, flexible, and cost-effective. Amazon S3 follows this same basic model of object storage.
How Amazon S3 works
Amazon S3 stores data objects in buckets, which are like containers that hold objects. Buckets are identified by a unique, user-assigned key. Objects are identified within buckets by a key and version ID assigned when the object is uploaded.
Amazon S3 objects offer metadata, which consists of name-value pairs that describe various object attributes. These include default metadata like object size, last modified date, etc. Users can also assign custom metadata tags to enrich the descriptions of objects.
S3 objects are stored in regions specified by the user. Regions consist of physical locations or data centers where Amazon stores the objects. Data replication across regions provides high durability and availability.
Data objects can range from 1 byte up to 5 terabytes in size. There is unlimited storage in S3, with subscribers paying only for what they use. Amazon handles infrastructure scaling as needed when objects are added.
S3 uses a REST API and HTTP verbs like GET and PUT to retrieve and write objects. It offers extensive security controls and encryption options. Features like versioning and lifecycle management add additional capabilities.
Object storage vs. block storage
Block storage divides data into evenly sized blocks or chunks and stores them as separate pieces, each with a unique address. Block storage allocates a fixed amount of storage capacity that is connected to a server. Common block storage devices include SAN and NAS devices, as well as cloud block storage like Amazon EBS.
Block storage works well for structured data that needs quick access, like databases or transaction-based workloads. The main disadvantages are the fixed capacity, hardware dependence, and scaling challenges.
Object storage manages data as objects instead of blocks. The objects contain the data, metadata, and globally unique ID. It uses a simple HTTP-based API to store and retrieve objects. Object storage is optimized to support massive amounts of unstructured data.
The advantages of object storage include:
- Flexible, pay-as-you-grow scalability.
- Durability and availability through replication.
- Metadata enables discoverability and searchability.
- Works well for large amounts of unstructured data.
The downsides of object storage include:
- Higher latency to retrieve objects compared to block storage.
- Not suitable for transactional or frequently changing workloads.
- Ecosystem around it is still maturing.
Why Amazon S3 is object storage
Looking at its architecture and features, it is clear why Amazon S3 is considered object storage:
- Data is stored as objects in buckets instead of using a file system hierarchy.
- Unique keys identify each object within buckets.
- Objects contain data, metadata, and an ID.
- REST API and HTTP verbs are used to GET/PUT objects.
- Highly scalable and durable architecture.
- Pay only for what you use and grow on demand.
- Primarily used for unstructured data like photos, videos, logs, etc.
The reliance on objects, metadata, REST API, and the design for scale-out storage of massive amounts of unstructured data all point to Amazon S3 being an object storage service versus a traditional block storage system.
Use cases well suited for Amazon S3
Here are some ideal use cases for using Amazon S3 object storage:
- Backup and archival: The high durability and low cost make S3 good for backups, archives, and long term data retention.
- Big data analytics: S3 works well for storing large data sets used for analytics and data lakes.
- Content repository: S3 can store huge amounts of photos, videos, documents that can be accessed from anywhere via HTTP requests.
- Hybrid cloud storage: Data can be stored securely in S3 and accessed from an on-premises system or application.
- Static website hosting: Simple websites with static content can be hosted directly from S3 buckets.
- Edge caching: S3 combined with CloudFront provides a CDN for fast delivery of static content.
Comparison of S3 vs. block storage
| Feature | Amazon S3 Object Storage | Block Storage (EBS) |
|---|---|---|
| Data architecture | Objects containing data, metadata, and ID | Divides data into evenly sized blocks |
| Access method | REST API with HTTP GET/PUT requests | Low-level block protocol (iSCSI/SCSI) |
| Scalability | Designed to scale out across servers | Constrained by fixed volume size |
| Use cases | Backup, archives, content repositories, big data analytics | Transactional DBs, boot volumes, ephemeral storage |
| Durability | 99.999999999% (11 9’s) | Designed for 99.8-99.9% durability |
| Pricing | Pay-as-you-go based on usage | Fixed prices based on volume size |
As the table illustrates, S3 and block storage like EBS differ significantly in architecture, use cases, scalability, durability, and pricing models.
Conclusion
Amazon S3 is clearly in the category of object storage versus traditional block storage systems. Its architecture stores data as objects in flat buckets, unlike block storage which organizes data in sectors and tracks. The use of objects, REST API, metadata, and scale-out design all point to Amazon S3 being an object store.
The unlimited capacity, high durability, and pay-as-you-go pricing make S3 ideal for large amounts of unstructured data. Backup, archives, content repositories, and big data analytics are perfect use cases for S3 object storage.
While block storage like EBS has some overlap, its sweet spot is for transactional, high-performance workloads that need consistent latency. For massive scale, unlimited capacity, and support for unstructured data, object storage like Amazon S3 is the clear choice.