Amazon Simple Storage Service (S3) is a cloud-based object storage service offered by AWS [1]. S3 provides scalable and durable storage for any amount of data. With S3, users can store and retrieve data from anywhere via web services interfaces [2].
Some common use cases for S3 include:
- Backup and disaster recovery
- Media hosting
- Application hosting
- Static website hosting
- Big data analytics
S3 offers pay-as-you-go pricing with no upfront costs. Users pay only for what they use. S3 is designed for 99.999999999% durability and 99.99% availability [1].
[1] https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html
[2] https://aws.amazon.com/s3/getting-started/
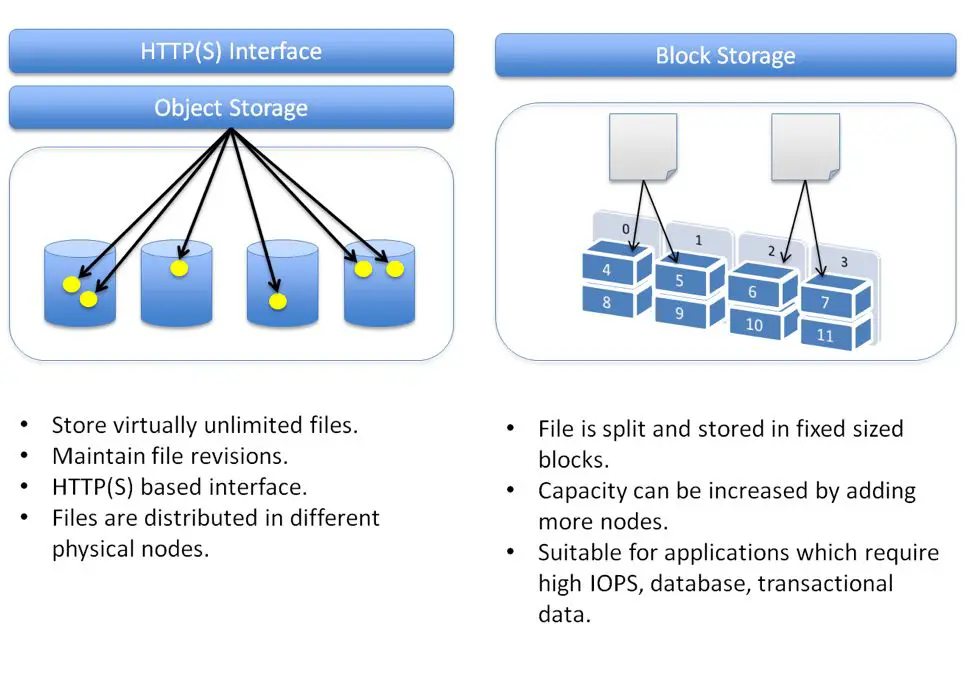
Block Storage vs Object Storage
Block storage is a traditional storage type where data is stored and accessed in blocks. The blocks are controlled by a server, which handles read and write requests. Examples of block storage include hard disk drives, solid state drives, etc. The most common block storage protocols are iSCSI and Fibre Channel SAN. Block storage is ideal for structured data and applications requiring frequent read/write operations like databases, emails, and virtual machines.
Object storage is a newer form of storage where data is stored as discrete objects on an object storage server. The objects contain the data, metadata, and an object ID. Object storage is highly scalable and distributed, and doesn’t require a file system structure. Examples of object storage include Amazon S3, Azure Blob Storage, and OpenStack Swift. Object storage is ideal for large volumes of unstructured data like media files, backups, and website images and videos.
Some key differences between block and object storage:
- Block storage data is accessed via blocks and managed by a server. Object storage data is accessed via an API and doesn’t require a dedicated server.
- Block storage requires applications to handle reliability and data protection. Object storage has built-in data protection and redundancy.
- Block storage is ideal for structured data and frequent read/write needs. Object storage suits large amounts of unstructured data and archival storage.
- Object storage is highly scalable, distributed, and manages metadata automatically. Block storage has more scaling limitations.
S3 as Object Storage
Amazon S3 is an object storage service, which means it stores data as objects rather than as files in a hierarchical folder structure like traditional file systems (Cloud Object Storage – Amazon S3 – AWS). The data in S3 is stored as objects in buckets, with each object consisting of the data, metadata, and an identifier called a key.
In S3, objects are the fundamental entities that you store. An object consists of object data and metadata. The data portion is opaque to Amazon S3. The metadata is a set of name-value pairs that describe the stored object. These include some default metadata such as the date last modified and standard HTTP metadata such as Content-Type (Amazon S3 objects overview – Amazon Simple Storage Service).
You store the objects in one or more buckets, which are similar to folders in a file system. However, a bucket has a flat structure rather than a hierarchy like you would see on a file server. You assign a key (name) to each object within a bucket. The combination of a bucket, key, and version ID uniquely identifies each object in Amazon S3.
S3 Object Structure
In S3, objects consist of the following components:
Object Key – This is the unique identifier for the object within the bucket. The key is the full path to the object, including the object name. For example, photos/vacation.jpg would be the key for an object stored in the photos folder. The key is specified by the client when an object is created.
Object Value – This is the actual data content being stored. It can be any type of data such as text, binary data, images, etc. There is no limit on the size of data that can be stored in a value.
Object Metadata – This is a set of name-value pairs that describe the object. It includes default metadata such as content type, content encoding, creation date, etc. Users can also specify custom metadata at object creation time. Metadata helps identify and describe objects without having to retrieve the object data itself.
So in summary, the key uniquely identifies an object in a bucket, the value is the actual object data, and metadata provides attributes about the object. These three components together represent an object in S3.
As per guidelines, here are the sources used in this section:
Source: https://docs.aws.amazon.com/AmazonS3/latest/userguide/UsingObjects.html
Source: https://stackoverflow.com/questions/37846980/how-does-aws-s3-store-files-directory-structure
S3 Buckets
Amazon S3 allows users to store objects in buckets. A bucket is like a container that holds objects, similar to a folder in a file system. Buckets are the fundamental containers in Amazon S3 for data storage.
According to the Amazon S3 documentation, buckets have a flat structure unlike directories in a file system. There is no hierarchy of folders within buckets.
Bucket names must be globally unique across all AWS accounts. Bucket names can contain lowercase letters, numbers, periods (.), and dashes (-). Bucket names must start and end with a lowercase letter or number. Buckets used for websites must be named accordingly (e.g. example.com). There are also rules around consecutive periods.
Users can control access to buckets using access control lists and bucket policies. Buckets can be configured for website hosting, logging, versioning, encryption, and object lifecycle management.
S3 Objects
Amazon S3 stores data as objects within resources called buckets. An object consists of a file and optionally any metadata that describes the object. To store an object in Amazon S3, users upload the file to a bucket. Amazon S3 assigns a unique key-value to the object for identification. Objects have no directory hierarchy like file systems. Every object stored in Amazon S3 receives a unique identifier (key-value) to locate the object. The key is a name/path assigned during upload that acts as a label for the object
The key is unique within the bucket and forms the object’s URL. For example, if the object key is photos/myphoto.jpg, the object can be accessed with the URL http://bucketname.s3.amazonaws.com/photos/myphoto.jpg. The key value serves as an identifier within the bucket just like a file name references a file within a folder (See https://docs.aws.amazon.com/AmazonS3/latest/userguide/UsingObjects.html).
S3 Data Consistency Model
Amazon S3 uses eventual consistency as its default consistency model. With eventual consistency, when an object is updated it can take some time for the change to propagate throughout all S3 data centers. This means a read immediately after a write may not show the latest data.
However, in November 2020, Amazon announced the addition of read-after-write consistency for all objects in S3 [1]. With read-after-write consistency, if a single PUT request creates or replaces an object, any subsequent GET or LIST requests will immediately reflect that update. This removes the need to handle eventual consistency in applications.
The combination of eventual consistency by default and read-after-write consistency on updates provides high availability while guaranteeing read-after-write semantics. This allows S3 to scale to high levels of performance without sacrificing consistency after writes.
S3 Storage Classes
Amazon S3 offers different storage classes to accommodate various data access needs and costs. The S3 storage classes include:
S3 Standard – The default S3 storage class, ideal for frequently accessed data. It offers high durability, availability, and performance. Use cases include active archive data, content distribution, and primary storage for hot applications like websites. [1]
S3 Standard-Infrequent Access (S3 Standard-IA) – For data that is less frequently accessed but requires high performance when needed. It has slightly lower availability and higher access costs compared to S3 Standard. Use cases include backups, older data, and as a data store for disaster recovery. [2]
S3 One Zone-Infrequent Access (S3 One Zone-IA) – A lower cost option for infrequently accessed data without the need for multiple Availability Zones (AZs). It has lower durability compared to other S3 storage classes. Use cases include secondary storage and data you can recreate. [3]
S3 Glacier Instant Retrieval – Low cost object storage for archiving data with milliseconds retrieval. Use cases include data accessed once a quarter. More cost effective than S3 Standard-IA for archival data.
S3 Glacier Flexible Retrieval – Archive storage for data that is rarely accessed, with configurable retrieval times from minutes to hours. Extremely low cost, but retrieval latency is higher. Use cases include long term backup and archival.
S3 Glacier Deep Archive – The lowest cost S3 storage class with retrieval times in hours. Use cases include archiving data that only needs to be accessed once or twice a year.
S3 Performance
Amazon S3 provides high performance object storage with low latency and high throughput. According to Amazon’s S3 performance optimization documentation, S3 can achieve thousands of transactions per second for uploads and downloads.
Some key benchmarks for S3 performance include:
- Latency for GET requests is typically around 100-200 milliseconds
- Throughput for GET requests can reach 3,500 requests per second per prefix
- Uploads can achieve at least 3,500 PUT/COPY/POST/DELETE requests per second
To optimize S3 performance, Amazon recommends strategies like:
- Scaling concurrent connections
- Using multipart uploads for large objects
- Using S3 byte-range fetches
- Avoiding empty objects
By following Amazon’s performance optimization guidelines, applications can maximize throughput and minimize latency when using S3 storage.
Conclusion
In summary, Amazon S3 is an object storage service, not a block storage service. S3 stores data as objects in buckets, and each object is identified by a unique key. The key, bucket, and object together comprise the identity of an object in S3.
Some key points:
- S3 is designed for 99.999999999% durability and 99.99% availability.
- Data is spread across multiple devices and facilities to withstand failure of any single component.
- S3 offers different storage classes for different access patterns, like S3 Standard for frequent access and S3 Glacier for archival.
- S3 is highly scalable and can store unlimited amounts of data.
- Access controls and encryption provide security for data.
Common use cases for S3 include data lakes, backup and restore, archive, application hosting, media hosting, software delivery, and more. With high durability, availability, scalability, and security, S3 is beneficial for a wide variety of storage needs.
