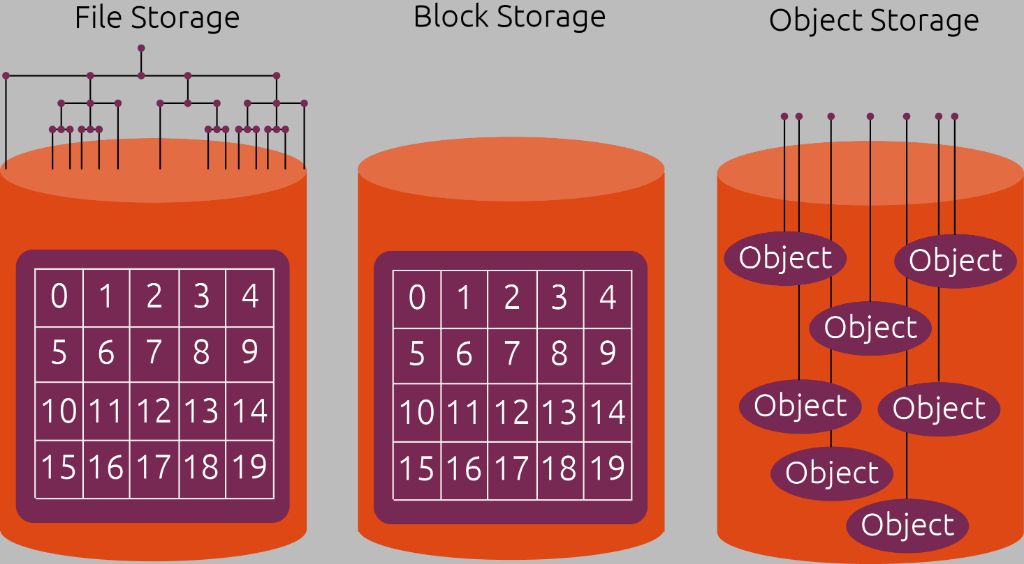
Block storage is a key component of cloud computing and data storage systems. There are two main types of block storage: block level storage and file level storage. Block storage stores data in fixed sized blocks, while file storage stores data in files. Understanding the differences between these two types of block storage is important for determining the right storage system for your needs.
What is Block Storage?
Block storage is a data storage technology that is used to store data in fixed size blocks, called blocks. Each block acts as an individual hard drive. Block storage is used as the underlying storage for disk volumes in storage area networks (SANs). It allows you to mount drives or volumes to servers for data storage and retrieval.
Some key characteristics of block storage include:
- Stores data in fixed size blocks
- Blocks act as virtual drives that can be mounted to servers
- Very low latency data access
- Supports random reads/writes very efficiently
- Volume sizes can be easily expanded by adding more blocks
- Allows for redundancy and high availability with replication and clustering
Block storage is commonly used for databases, email servers, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems and other transactional applications that require fast random access. It is also used for boot volumes containing operating systems.
Two Types of Block Storage
The two main types of block storage are:
- Block Level Storage
- File Level Storage
Let’s look at each of these in more detail.
Block Level Storage
Block level storage, sometimes referred to as block storage, stores data in fixed size blocks. Each block acts as an independent storage volume that can be connected to a server. Some examples of block level storage technologies include:
- Storage Area Network (SAN)
- Direct Attached Storage (DAS)
- Network Attached Storage (NAS)
- iSCSI Storage
- Amazon EBS Volumes
- Azure Virtual Hard Disks
With block level storage, each block can be managed independently. Blocks from multiple storage devices can be aggregated together to create larger volumes if needed.
Block level storage works at the disk level. The operating system manages the filesystem and file abstraction on top of block level storage volumes. This allows the OS to control how data is organized into files which are read and written by applications.
Access to block level storage is very fast because data can be read and written directly in fixed sized blocks. This makes it ideal for transactional systems like databases that perform a high number of small random I/O operations.
File Level Storage
In contrast to block level storage, file level storage manages data in a hierarchical file system rather than blocks. Examples of file level storage include:
- Network Attached Storage (NAS)
- Object Based Storage
- Amazon S3
- Azure Files
With file level storage, data is stored in files rather than blocks. The storage system itself manages the filesystem rather than the OS.
This provides a shared storage system accessed over a network that multiple clients can access. Clients mount file level storage to access and manage files directly via network protocols like NFS and SMB.
File access requires operating through the filesystem layer, so access times tend to be slower than block storage. File level storage is better suited for storing large files like media, documents, and backups that are sequentially accessed.
Comparing Block Level vs. File Level Storage
Here is a comparison of some key attributes between block level and file level storage:
| Attribute | Block Level Storage | File Level Storage |
|---|---|---|
| Access method | Mounted directly to servers | Accessed over network protocol |
| Performance | Very low latency | Higher latency |
| Workload | Transactional, databases | Sequential, large files |
| Redundancy | Replication, clustering | Replication |
| Scalability | Add more blocks | Scale out filesystem |
To summarize, block level storage provides low latency, fast access to volumes mounted directly on servers to support transactional workloads. File level storage allows shared access over a network using a distributed filesystem to store large volumes of files and support big data applications.
Block Level Storage Architecture
Block level storage architectures provide storage volumes to servers by abstracting the underlying disk hardware. The key components of a block level storage architecture include:
- Servers – The servers that connect to and mount block level storage to access storage volumes.
- Storage Nodes – These provide the abstracted block level storage volumes to servers.
- Protocol Endpoints – Allow the servers to communicate with the storage nodes over standard protocols like iSCSI or Fibre Channel.
- Disks/Drives – The underlying disk drives that provide the physical storage capacity.
- RAID Arrays – Group disks together for performance and redundancy.
- Storage Fabric – The network that connects the storage nodes and servers.
For example, in a SAN architecture, the SAN storage controller nodes provide block level storage over Fibre Channel to multiple servers. The storage volumes provided by the SAN nodes consist of RAID groups of drives. This creates redundant shared storage that can be accessed at the block level by the connected servers.
Virtualized Block Storage
Block level storage architectures have also been heavily virtualized in cloud computing environments. Cloud block storage allows instances to mount virtual storage volumes called block devices.
Some examples of cloud block storage services include:
- Amazon Elastic Block Store (EBS) Volumes
- Azure Virtual Hard Disks
- Google Persistent Disks
These present virtual block devices that can be attached to cloud compute instances. Under the hood, they utilize large pools of commodity storage hardware to deliver the block volumes.
File Level Storage Architecture
File level storage architectures provide access to data organized in hierarchical filesystems over a network using standardized protocols. The main components of a file level storage architecture include:
- Client Systems – The client computers that mount and access file level storage over the network.
- Meta Data Servers – Track filenames, directories, and attributes of files on the storage system.
- Storage Nodes – Provide capacity using commodity storage hardware.
- Network Fabric – The high speed network that connects clients to the storage nodes.
For example, in a NAS architecture, metadata servers keep track of the file system directory hierarchy and attributes. Storage nodes provide the capacity over NFS, CIFS or SMB shared storage protocols that clients can access and mount as remote filesystems.
Scale-Out Filesystems
File level storage architecture has also evolved with scale-out network filesystems designed for cloud computing environments. These scale-out filesystems distribute files across multiple storage nodes, providing aggregation of capacity into a single global namespace.
Some examples of distributed scale-out filesystems include:
- HDFS – The Hadoop Distributed File System
- Amazon S3 – Simple Storage Service
- Azure Blob Storage
- Google Cloud Storage
Rather than local filesystem semantics, these provide an object storage abstraction over distributed storage nodes. Large numbers of storage nodes can be added to these cluster filesystems to scale capacity and throughput.
Block Level vs. File Level Storage Comparison
Here is a summary comparing block level and file level storage architectures:
| Attribute | Block Level Storage | File Level Storage |
|---|---|---|
| Access method | Direct attached to servers | Over network protocol |
| Latency | Very low | Higher latency |
| Workloads | Transactional systems | Large files, big data |
| Protocols | iSCSI, FC, Infiniband | NFS, SMB, CIFS |
| Redundancy | Replication, clustering | Replication |
| Scalability | Scale up | Scale out |
In summary, block level storage provides directly attached, low latency storage access suitable for transactional processing while file level storage provides shared file access over the network better suited for large files and big data analytics applications.
When to Use Block Level vs. File Level Storage
So when should you use block level versus file level storage? Here are some general guidelines:
Use Block Level Storage for:
- Transactional systems like databases
- Applications that need very low latency access
- Boot volumes and operating systems
- Real-time workloads like messaging and streaming
Use File Level Storage for:
- Store large volumes of data like media files, documents
- Big data analytics platforms like Hadoop
- Backups and archives
- Software development repositories and logs
Many systems use a combination of both block level and file level storage. For example, you may boot a server from a block level boot volume and then store data files on a file level NAS device.
Block Level vs. File Level Storage in the Cloud
Cloud computing environments take advantage of both block level and file level storage in different services. Here are some examples:
Cloud Block Storage Services
- AWS EBS Volumes
- Azure Virtual Hard Disks
- GCP Persistent Disks
These provide virtual block level storage devices that can be provisioned on demand and attached to cloud compute instances.
Cloud Scale-out Filesystems
- AWS S3
- Azure Blob Storage
- Google Cloud Storage
These services provide highly scalable object storage built on distributed filesystems. They can store enormous volumes of data accessible over HTTP.
Cloud NAS Services
- AWS EFS
- Azure File Storage
- GCP Filestore
These cloud services provide shared file system storage accessible over NFS and SMB protocols that can be mounted on multiple instances.
By leveraging different storage services, applications can get the benefits of both fast, low latency block level storage as well as highly scalable file level storage on demand.
Block Level Storage Use Cases
Here are some common use cases and examples of block level storage deployments:
Virtual Machine Disks
One of the most common uses of block storage is for virtual machine disks. Hypervisors like VMware, Hyper-V, KVM and Xen provide virtual block devices that can be mounted to virtual machines. These virtual disks sit on top of real block level storage like SANs and iSCSI.
Database Servers
Databases like Oracle, MySQL, Cassandra, MongoDB and Microsoft SQL Server are perfect workloads for block level storage. They perform large volumes of small random I/O operations that require very low latency. Direct attached SAN and NAS storage provides the fast block access databases need.
Transactional Systems
Transactional systems like payment processors, financial trading systems, e-commerce platforms, CRM and ERP systems all rely on fast block level storage. These applications perform many small reads and writes that need millisecond response times.
Big Data
Big data systems like Hadoop can leverage block storage for the HDFS NameNode metadata server to provide faster access. The block storage provides lower latency access to the metadata than sharing the same storage with the rest of the HDFS cluster.
High Performance Computing
HPC systems for research, engineering, and scientific computing applications take advantage of parallel block storage to achieve huge throughput and IOPS. Large SAN and clustered storage provide the shared block access concurrently to thousands of compute nodes.
File Level Storage Use Cases
Here are some examples of common file level storage use cases:
Media Storage and Processing
The huge capacity and throughput of file level storage makes it ideal for storing and processing video, images, audio and multimedia files. Media editing platforms leverage SAN and NAS storage to provide high speed access to render and process gigabyte sized files.
Backups and Archives
File level storage is heavily used for backups and archives. Backup software like Veeam and Commvault write backups as large files rather than block level images. Tape libraries also store backups in tape files written sequentially.
Software Development
Source code repositories and version control systems like GIT, SVN and CVS rely on fast file level storage. Shared file systems provide development teams parallel access to huge code repositories stored on NAS devices.
Virtual Server Storage
While virtual machine disks use block storage, virtual servers still need access to file level storage for things like logging, configuration files and application data. NAS devices and filers are perfect for storing these large files.
Big Data Analytics
Hadoop and big data platforms like Apache Spark leverage distributed scale-out filesystems for storing huge datasets that need analytic processing. Object stores like AWS S3 provide enormous capacity for data lakes.
Conclusion
Block level and file level storage provide fundamentally different methods of storing and accessing data. Block storage excels at low latency for transactional workloads while file storage is better for large media files and big data. Most organizations use a mix of block and file storage in on-prem and cloud environments.
Understanding when to apply block versus file storage and the strengths of each approach enables building robust and well-architected data storage infrastructure.
