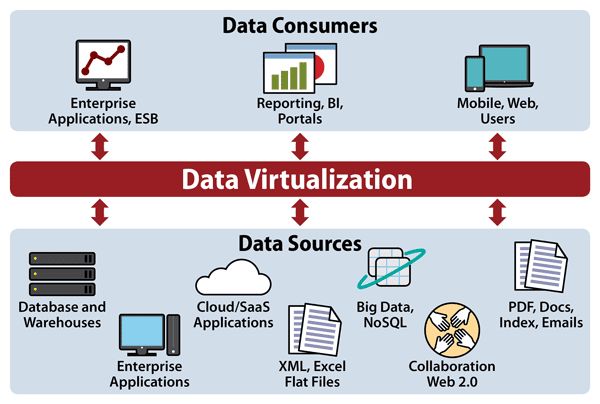
Data virtualization is a software architecture pattern in which data from multiple sources across an organization are presented to applications and users as a single logical data layer. This provides unified access to distributed data without having to duplicate data into a central repository. Data virtualization serves as an abstraction layer that separates data consumers from the technical complexities of where data is located and how it is stored and formatted. The key benefits of data virtualization include increased data agility, reduced costs, improved analytics, and greater data accessibility.
What is data virtualization?
Data virtualization provides a virtual data layer that allows applications and business users to access data from multiple heterogeneous sources through a single, unified interface. This virtualization acts as an abstraction layer that hides the technical complexities of where data is physically stored, how it is formatted, and how it is accessed. The virtualization software handles translating data into a consistent format, combining it from disparate sources, and delivering it to data consumers in real-time when queried. This enables unified data access without requiring data replication into a single repository.
Some key capabilities of data virtualization include:
- Federated queries – Query data from multiple sources concurrently as if it existed in one place.
- Real-time data services – Access integrated data on demand instead of batch ETL process.
- Caching and optimization – Improve performance by caching frequently accessed data.
- Abstraction and transformation – Present data in consistent semantics and formats.
- Security and governance – Apply access controls and manage usage policies.
By providing a flexible virtual abstraction layer, data virtualization facilitates unified data access and governance without disrupting existing infrastructure or moving data from source systems.
What are the benefits of data virtualization?
Implementing data virtualization architecture can deliver numerous benefits for an organization:
Increased data agility
Data virtualization makes data integration much more agile compared to traditional ETL (extract, transform, load). Adding or modifying data sources can be done without having to rewrite and retest entire pipelines. New data sets can be made available to users much faster. This increased agility enables organizations to respond better to changing business needs.
Reduced costs
By eliminating the need to create redundant copies of data in a central repository, data virtualization significantly reduces infrastructure and overhead costs. Organizations save on storage, hardware, and administrative expenses. Virtualization also reduces costs by consolidating integration processes that were previously duplicated across units.
Improved analytics
With data available from more sources in a unified schema, data virtualization improves analytics with a more complete view of information. Queries can incorporate live operational data instead of just stale data in static repositories. This enables more accurate reporting, predictions, and recommendations.
Greater data accessibility
Data virtualization makes consolidated data readily accessible to more users across an organization. Business users can access vital data directly without having to request extracts and transformations. This expands business insights and reduces time-to-value.
Increased productivity
By reducing the time and effort needed for data integration tasks, data virtualization allows IT and analytics teams to focus on higher-value work. Less time spent on ETL and data preparation frees staff to collaborate on developing core systems and advanced analytics models.
Reduced risk
Data virtualization reduces risk in areas like disaster recovery because data remains in source systems. It also limits risk of introducing data errors through transformation since data is accessed in real-time. With proper governance, data virtualization limits proliferation of separate data copies across systems.
What are the use cases for data virtualization?
Here are some of the top use cases where data virtualization delivers significant business value:
Master data management (MDM)
Data virtualization can act as a virtual master data layer to provide unified views of business entities like customers, products, suppliers, etc. This simplifies MDM without moving master data into a central repository.
Business intelligence and analytics
Data virtualization enables BI tools to query and combine live data from multiple transactional systems and data warehouses. This provides more accurate analytics and dashboards.
Cloud data integration
Data virtualization is ideal for integrating data across cloud and on-premise systems into a unified architecture. This is a key enabler of hybrid cloud strategies.
Mobile and IoT applications
Data virtualization provides a cost-effective way to integrate device and sensor data from disparate endpoints into unified services and analytics.
Data services consolidation
Organizations can use data virtualization to consolidate multiple redundant data services and siloed efforts into shared services with master data and reusable logic.
Agile data hubs
Data virtualization enables creating agile, business-owned data hubs that span domains for cross-functional analytics without moving data.
Legacy modernization
Abstracting legacy systems behind a virtual layer facilitates linking them to modern analytics while mitigating risk and cost of replacing them.
What are the key capabilities required for data virtualization?
For an enterprise to effectively leverage data virtualization, the virtualization platform should provide certain key technical capabilities:
- Federated query engine – Query and combine data from diverse sources like relational and NoSQL databases, files, cloud apps.
- High-performance caching – Local caches of source data sets improves response times.
- Data abstraction – Map heterogeneous data to common business-friendly semantics and formats.
- Data services and APIs – Expose virtualized data as reusable services with standard APIs.
- Security – Fine-grained access controls and auditing of data usage and queries.
- Transaction support – Maintain data consistency across updates to underlying sources.
- Change data capture – Detect and surface data changes across sources without full scans.
- Monitoring and admin – Operational tools to manage virtualization jobs and SLAs.
Leading data virtualization platforms like Denodo provide robust implementations of these key capabilities to deliver business value.
What are some leading data virtualization products and vendors?
Some prominent data virtualization platforms on the market include:
Denodo Platform
Denodo provides an enterprise-grade data virtualization software platform. It includes capabilities for federated queries, real-time data services, caching, security, and administration across cloud and on-premise sources. Denodo has become a leader in the data virtualization market.
Oracle Data Service Integrator
Part of Oracle’s Exadata ecosystem, this integrates data from Oracle and non-Oracle sources. It focuses on SQL support and optimizing performance on Exadata Database.
IBM Cloud Pak for Data
IBM offers data virtualization capabilities as part of its Cloud Pak for Data platform. This is geared for hybrid cloud deployments on RedHat OpenShift.
Informatica Cloud Data Integration
Informatica provides data virtualization features as part of its cloud platform. This supports real-time virtual data access, transformation, and delivery services.
SnapLogic Elastic Integration
SnapLogic offers data virtualization functions like data abstraction, lookups, and caching as part of its iPaaS (integration Platform-as-a-Service) offering focused on self-serve integration.
TIBCO Data Virtualization
Part of TIBCO’s Connected Intelligence platform, this data virtualization toolset aims to bridge real-time and historical data access.
CData data virtualization
CData focuses on relational access to SaaS, NoSQL, and API data sources via virtual tables using SQL and standard connectors.
How does data virtualization differ from an ETL data warehouse?
| Data Virtualization | ETL Data Warehouse | |
|---|---|---|
| Data movement | No data movement or replication | Replicates data into warehouse repository |
| Latency | Real-time access | Batch updates on periodic schedule |
| Data stores | Unified virtual access across sources | Single repository store |
| Workloads | Analytics and operational apps | Analytics-focused |
| Agility | Flexible to change | Rigid, requires re-engineering |
| Costs | Reduces infrastructure costs | Expensive to scale |
Data virtualization complements data warehousing in a modern data architecture by offloading operational workloads and providing unified data services.
What are some key challenges with implementing data virtualization?
Some potential challenges to address with data virtualization include:
Performance tuning
Achieving optimal query performance across a variety data sources with differing latencies requires careful optimization and caching.
Data consistency
Ensuring data points stay in sync across sources and loads requires proper transaction handling.
User training
Accustomed to traditional ETL workflows, users may require guidance on effectively querying virtualized data.
Security controls
Granular access policies must be implemented to prevent unauthorized usage while providing access needed for analytics.
Change management
Transitioning from ingrained data warehousing practices takes thoughtful change management.
Cost optimization
Balancing performance vs infrastructure costs takes planning as data needs grow.
How can data virtualization risks be mitigated?
Proper planning and governance helps mitigate key risks with data virtualization projects:
- Start with focused use cases – Implement virtualization incrementally for specific high-value workflows before expanding scope.
- Pilot with non-critical data – Test capabilities using lower sensitivity data to evaluate performance.
- Scale carefully – Monitor workloads closely and expand platform resources gradually to manage costs.
- Implement access controls – Leverage granular role-based access policies to prevent data abuse.
- Mask sensitive fields – Use data masking techniques for fields like credit card or social security numbers.
- Communicate SLAs – Set user expectations for system availability and performance.
- Create data stewards – Clearly define responsibilities for curating virtual data models.
Conclusion
Data virtualization delivers significant business value by providing unified real-time data services across disparate sources. The approach increases agility, reduces costs, and improves analytics compared to traditional data integration techniques. Leading solutions like Denodo enable robust enterprise implementations. However, proper testing, security controls, and governance must be implemented to mitigate risks. With the right strategy and platform, data virtualization provides organizations with vital technologies to unlock the value of information.