RAID stands for “Redundant Array of Independent Disks”. It is a data storage technology that combines multiple disk drive components into a logical unit. The different disks in a RAID array are linked together so they appear as a single disk to the operating system. This allows optimized and redundant storage capacity, performance and reliability (Source).
The term RAID was first coined in 1987 by David Patterson, Randy Katz and Garth A. Gibson. In their 1988 technical report, “A Case for Redundant Arrays of Inexpensive Disks (RAID)”, they outlined the fundamental concepts behind RAID technology (Source). The purpose of RAID is to provide fault tolerance and improve performance by distributing and replicating data across multiple hard disks.
There are different RAID levels or configurations that offer various combinations of performance, capacity and fault tolerance. The most commonly used levels are RAID 0, RAID 1 and RAID 5.
RAID 5 Overview
RAID 5 is a storage technology that combines disk striping with distributed parity for redundancy and fault tolerance while still maintaining high performance and storage efficiency (1). It requires a minimum of 3 physical disks and is one of the most commonly used RAID configurations for businesses and data centers that require the increased performance of RAID 0 as well as the redundancy of RAID 1, but are looking to limit the cost overhead that results from Mirrored or Parity Drives (2).
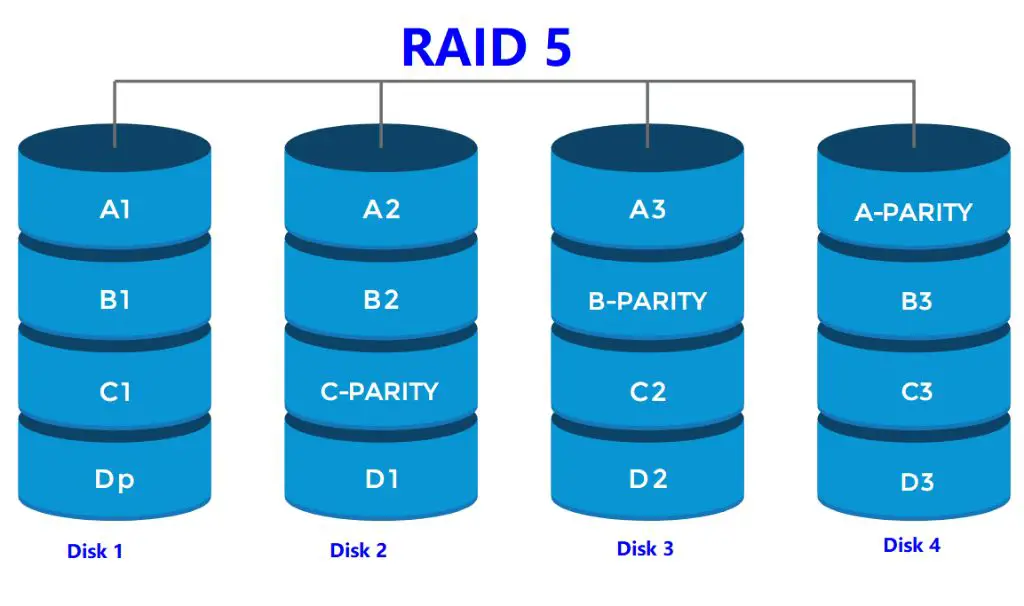
Data is broken down into blocks which are then striped and written across all the drives in the array simultaneously. The parity information is distributed amongst all the drives rather than being stored on a single dedicated drive. This distributed parity allows the array to sustain a single drive failure without losing access to data (1). If a drive fails, the missing portion of data can be recreated using the parity information stored on the remaining disks (1).
The benefits of RAID 5 primarily come from its combined use of disk striping and distributed parity. Striping provides high throughput and I/O performance as data requests can be processed in parallel across multiple disks. The distributed parity allows for efficient use of disk space compared to RAID 1 mirroring while still providing redundancy and fault tolerance (2). RAID 5 provides a nice balance of performance, redundancy, and cost efficiency for many workloads (3).
Sources:
(1) https://www.techtarget.com/searchstorage/definition/RAID-5-redundant-array-of-independent-disks
(2) https://www.ibm.com/docs/en/i/7.3?topic=concepts-benefits-raid-5-protection
(3) https://www.easeus.com/storage-media-recovery/raid-5.html
Data Striping
Data striping refers to splitting data evenly across multiple drives1. With RAID 5, data is divided into blocks called “stripes” that get distributed across all the drives in the array. The stripe size, also known as the chunk size, is the size of each block of data. A common chunk size for RAID 5 is 64KB or 128KB.
Striping enhances performance because multiple drives can be accessed simultaneously to read and write data. When a file is written to a RAID 5 volume, the data is divided into stripes that are spread randomly across the drives. This allows the workload to be shared evenly by all the disks, improving efficiency compared to a single drive.
Distributed Parity
RAID 5 uses a distributed parity scheme to provide fault tolerance while avoiding the capacity penalty of disk mirroring. Parity information is distributed across all disks in the array, unlike RAID 3 which dedicates an entire disk to parity. Here’s how distributed parity works in RAID 5:
RAID 5 divides data into stripes and writes them across all disks in the array. In addition to the data stripes, it generates parity stripes using an XOR calculation. These parity stripes contain checksum data that can be used to reconstruct missing information in the case of a disk failure. The parity stripes are not stored on any single disk – instead, they are distributed across all disks.
For example, in a 3 disk RAID 5 array, disk 1 may contain data stripe A and the parity stripe for disks 2 and 3. Disk 2 may contain data stripe B and the parity stripe for disks 1 and 3. Disk 3 contains data stripe C and the parity for disks 1 and 2. This layout allows any single disk to fail without data loss, as the parity stripes on the remaining disks can reconstruct the missing information.
When new data is written to a RAID 5 volume, the parity stripes are recalculated to maintain fault tolerance. The distributed nature of RAID 5 parity enables excellent performance while also providing protection against disk failures.[1]
Fault Tolerance
One of the key features of RAID 5 is its ability to withstand a single drive failure without losing data. This is made possible through the distributed parity approach. With RAID 5, parity information is spread evenly across all the drives in the array, unlike RAID 4 where it is concentrated on a single dedicated parity drive.
If a single drive in a RAID 5 array fails, the data that was on that drive can be recalculated using the parity information spread across the remaining drives. This provides fault tolerance for up to one drive failure, ensuring continued access to data even if a drive crashes (Source 1). The array will run in a degraded state until the failed drive is replaced, at which point the data can be rebuilt onto the new drive. This fault tolerant capability allows RAID 5 to provide high availability despite drive failures.
However, RAID 5 arrays can only withstand a single drive failure. If a second drive fails before the first failed drive is replaced and rebuilt, catastrophic data loss will occur. For this reason, RAID 6 which can tolerate up to two drive failures is sometimes used instead of RAID 5 when higher fault tolerance is required (Source 2).
Performance
RAID 5 provides good performance for read operations but write performance is slower compared to RAID 0 due to the parity calculations.[1] The write penalty for RAID 5 is a result of the parity information needing to be updated each time data is written. This requires the RAID controller to read the old data, compute the new parity, and write the new data and parity.
According to benchmarks, RAID 5 can achieve sequential read speeds up to 400-600 MB/s depending on the number of drives. Sequential write speeds are slower around 100-300 MB/s.[2] For transactional workloads involving random reads and writes, RAID 5 can provide between 20,000-50,000 IOPS.
In general, RAID 5 provides a good balance of performance and redundancy for applications that are read-intensive but still require write capabilities.
[1] https://arstechnica.com/civis/threads/linux-software-raid-5-performance-benchmarks-inside.139247/
[2] https://www.anandtech.com/show/3204
Expanding RAID 5
One advantage of RAID 5 is the ability to expand capacity by adding additional drives. To expand a RAID 5 array, you simply add a new physical disk that is equal to or larger than the existing disks in the array. The RAID controller will automatically incorporate the new disk into the array and expand the available space.
For example, if you have an 8 disk RAID 5 with 300GB disks, you could add a 600GB disk to expand the capacity. The RAID controller expands the array so it stripes data across 9 disks now instead of 8. The extra space provided by the larger 600GB disk is seamlessly added to the available storage pool.
The process works similarly if you want to replace smaller disks with larger ones. You remove a disk, insert a new larger one, let the RAID rebuild, and repeat for each disk you want to replace. Again the extra capacity is automatically added to the array.
One important consideration is that expanding or replacing disks in RAID 5 does require a rebuild process. This temporarily increases load on the remaining disks and could impact performance. It’s best to schedule expansions during maintenance windows.
Overall, expanding RAID 5 by adding disks is straightforward. But it’s essential to closely monitor the rebuild process and understand the temporary performance impact. With proper planning, expanding capacity is one of the key benefits of RAID 5’s flexible design.
Common Use Cases
RAID 5 is commonly used in small- to medium-sized business servers and workstations where maximum storage capacity is needed with a moderate level of redundancy. The main benefits of using RAID 5 are:
- Good balance between storage capacity and redundancy – You only “lose” the capacity of 1 drive compared to RAID 0.
- Allows for 1 drive failure without data loss – If a drive fails, data can still be accessed and the failed drive replaced.
- Better read performance than RAID 1 or RAID 10 due to data striping.
Some key considerations around using RAID 5:
- Not recommended for high performance applications due to the parity write penalty that slows write speeds.
- Not ideal for large drive arrays due to the rebuild time if a drive fails. The larger the drives, the longer it takes to rebuild.
- Higher risk of data loss in the event of a second drive failure during a rebuild compared to RAID 6.
Overall, RAID 5 provides a good option for cost-effective redundant storage where maximum read performance and capacity are needed, but not suitable for mission critical systems or heavy write workloads where RAID 10 would be a better option.
Alternatives to RAID 5
While RAID 5 has been a popular option for many years, it has some drawbacks that have led IT professionals to consider other RAID levels as alternatives. The two most common alternatives are RAID 6 and RAID 10.
RAID 6 is similar to RAID 5 in that it uses distributed parity and striping for redundancy and performance. However, RAID 6 uses a second distributed parity scheme, allowing for the failure of up to two drives without data loss. This added fault tolerance comes at the expense of some write performance compared to RAID 5. RAID 6 requires a minimum of four drives.
RAID 10 combines mirrored sets of drives into a single array using striping. This provides fault tolerance similar to RAID 5, but has better performance for read operations. However, RAID 10 requires more disks to achieve the same overall storage capacity as RAID 5. At least four drives are needed for a basic RAID 10 array.
Choosing between RAID 5 alternatives involves weighing priorities like storage efficiency, performance, and fault tolerance. RAID 6 provides excellent redundancy for critical data, while RAID 10 offers better performance for applications like databases. The decision depends on the specific use case and budget.
Conclusion
In summary, RAID 5 is a storage technology that combines block-level striping with distributed parity. It provides fault tolerance by allowing recovery from the failure of one drive in the array. The key benefits of RAID 5 include good read performance, the ability to withstand a single drive failure, and efficient storage capacity utilization. However, as drive capacities continue to increase, the rebuild times for failed drives also increase, which negatively impacts performance during rebuilds and increases the chance for data loss in the event of an additional drive failure.
Looking to the future, some experts predict the end of RAID 5 as drive sizes continue to grow. The prolonged rebuild times pose too high of a risk for such a critical system. Alternatives like RAID 6 or RAID 10 may become more prevalent for those needing redundancy and performance. However, RAID 5 is still commonly used today in many applications where uptime is not mission critical. The balance of storage efficiency, fault tolerance, performance and cost make RAID 5 a good option for many use cases.