RAID (Redundant Array of Independent Disks) is a data storage technology that combines multiple disk drive components into a logical unit. RAID can provide increased storage performance and reliability through redundancy.
There are different levels of RAID that provide varying combinations of performance, capacity and resilience. Some common RAID levels include:
- RAID 0 – Data striping across multiple disks for high performance.
- RAID 1 – Disk mirroring for redundancy.
- RAID 5 – Block-level striping with distributed parity for redundancy.
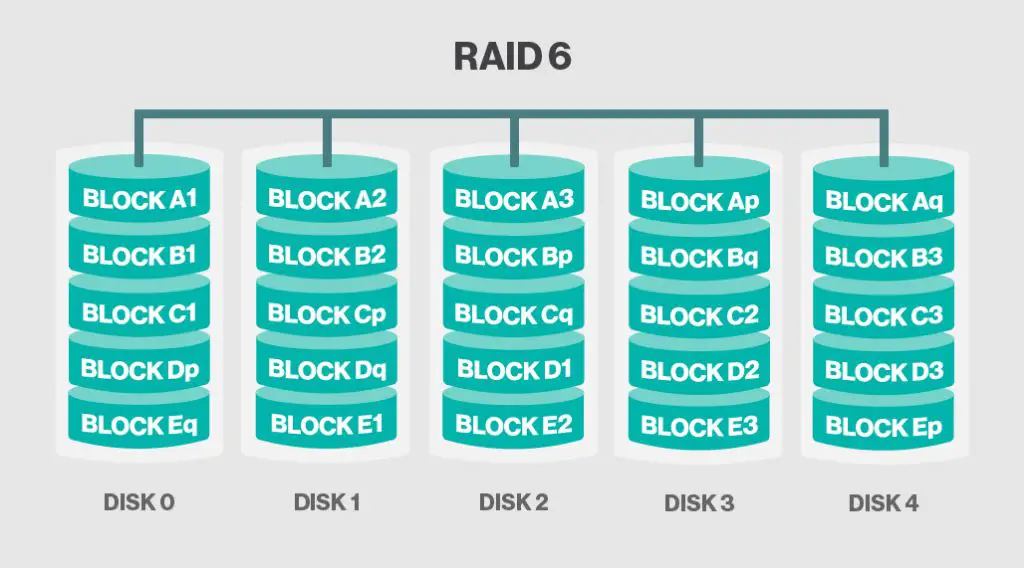
- RAID 6 – Block-level striping with double distributed parity.
Parity computation plays a key role in certain RAID levels like RAID 5, which distributes parity information across drives. The purpose of RAID parity is to provide redundancy and fault tolerance. If a drive fails, the missing data can be recreated using the parity drive. This allows the RAID to continue operating with a failed drive until it is replaced.
What is Parity?
Parity is a method of detecting errors in data stored across storage drives in a RAID (Redundant Array of Independent Disks) system. It works by calculating and storing additional “parity” information that can be used to reconstruct data if a drive fails.
Parity computations involve XORing data across drives in the RAID array to generate parity information that gets written to a dedicated parity drive. By XORing the data on the remaining drives after a failure, the system can reconstruct the missing data from a failed drive using the parity drive. This provides redundancy and fault tolerance (Source).
For example, in a RAID 5 array with 4 data drives, the parity is calculated by XORing data from the 4 drives and stored on a 5th dedicated parity drive. If one of the 4 data drives fails, the data can be recreated by XORing the data on the remaining 3 drives with the parity drive. This allows the RAID system to continue operating with no data loss despite a single drive failure.
How Parity is Used in RAID
The purpose of parity in RAID is to provide redundancy and fault tolerance in the event of a drive failure. Parity allows data to be reconstructed if a drive fails by performing an XOR calculation on the remaining data drives. The result of the XOR calculation is the parity data, which gets written to the dedicated parity drive(s).
Parity is calculated by performing an XOR logical operation across the corresponding bits on each data drive. For example, in a RAID 5 array with 4 data drives, a bitwise XOR would be performed on the first bits from each drive, then the second bits, and so on. The result is a parity bit that gets written to the parity drive. This parity data can then be used to recreate any missing data in the case of a drive failure.
The key difference between parity and mirroring is that parity requires less overall disk capacity. With mirroring, an entire duplicate (mirror) copy of the data is stored. Parity only requires enough storage for the parity calculation results rather than a complete second copy of the data. However, rebuilding a failed drive takes longer with parity than with a mirrored drive.
In summary, parity provides redundancy while minimizing overall storage capacity requirements compared to mirroring. But mirroring may provide faster rebuild times. The choice depends on the priorities for a given RAID implementation.
Sources:
https://www.quora.com/What-is-the-difference-between-a-mirror-and-a-parity-drive-in-RAID-arrays
RAID Levels with Parity
There are several common RAID levels that utilize parity to provide fault tolerance:
RAID 3
RAID 3 stripes data across multiple disks, with a dedicated parity disk used to store parity information. It provides good read performance by spreading reads across multiple disks, but write performance suffers due to the parity disk bottleneck. RAID 3 can withstand a single disk failure via the parity disk.
RAID 4
RAID 4 is similar to RAID 3, but it stripes blocks of data rather than individual bits. This helps improve write performance compared to RAID 3. Like RAID 3, RAID 4 dedicates a single parity disk. It can handle a single disk failure, but write performance may suffer due to the dedicated parity disk.
RAID 5
RAID 5 stripes blocks of data and parity across all disks in the array. Since parity is distributed, there is no single parity disk bottleneck. RAID 5 provides good read performance and improved write performance over RAID 3/4. It can withstand a single disk failure by using the remaining parity information to rebuild the lost data.
However, rebuild times are slow for large disks. Also, RAID 5 is vulnerable to a second disk failure during rebuild, which would cause data loss.
RAID 6
RAID 6 stripes data and parity like RAID 5, but uses an additional parity block for each set of data blocks. This “dual parity” provides fault tolerance for up to two disk failures. RAID 6 provides excellent protection, but write performance suffers due to the extra parity calculations.
RAID 6 is preferable for mission critical data where fault tolerance is more important than write speed. The added protection of dual parity makes RAID 6 less vulnerable than RAID 5 during rebuilds.
Calculating Parity
In parity RAID configurations like RAID 5, parity information is calculated using an XOR (exclusive OR) operation. This is a logical operation that results in 1 if one of the operands is 1. Otherwise, it results in 0. Here’s a simple example of how parity may be calculated in a RAID 5 array with 4 drives:
Drive 1: 1 0 1 1 0 1 0 0
Drive 2: 0 1 1 0 1 0 1 1
Drive 3: 1 1 0 1 0 1 0 1
Parity: 0 0 0 0 0 0 0 0
The parity drive starts with all 0s. Then the XOR operation is applied to each corresponding bit position across the data drives. In the first position, two of the drives have 1 and one has 0, so the result is 1. In the second position, two drives have 0 and one has 1, so the parity bit is also 1. This continues across each bit position, XORing the values to calculate the parity.
This allows the RAID system to recover data in case of a single drive failure. By XORing the data on the remaining drives with the parity drive, the system can reconstruct the missing data.
Calculating parity provides redundancy without duplicating data fully. But it requires heavy computation, typically handled by the CPU. Performance can suffer in write-heavy parity RAID systems (source).
Reading/Writing Data with Parity
In parity-based RAID, parity information is used to recover data in case of disk failure. Parity allows the system to reconstruct missing data by performing an XOR calculation on the remaining data blocks and the parity block.
For example, in a RAID 5 array with 4 data disks and 1 parity disk, if one data disk fails, the system can read the remaining data blocks and the parity block. It then uses XOR to calculate the missing data block contents. This provides fault tolerance and allows operations to continue with no data loss despite a failed disk.
A key consideration with parity RAID is the write penalty that occurs due to parity calculations. Each time new data is written to the array, the parity information must be updated to remain consistent. This requires reading the old data block, old parity, new data block, and recalculating parity, increasing the I/O operations per write.
Strategies like write-back cache, RAID stripes, and distributing parity updates across drives can help to optimize RAID performance. However, the fundamental parity write penalty remains a tradeoff for the increased fault tolerance.
Optimizing RAID Performance
There are several strategies that can help optimize the performance of RAID arrays.
One technique is avoiding unnecessary read-modify-write operations. With some RAID levels like RAID 5 and RAID 6 that use parity, writing new data requires the RAID controller to read the existing data and parity, recalculate the parity, and write the new data and parity to disk. This read-modify-write process can impact performance, especially for small random writes. Using larger stripes sizes, combining writes, and optimizing drive layouts can reduce unnecessary read-modify-writes.
Another optimization is to use RAID controllers with large caches. The cache on the RAID controller stores frequently accessed data and avoids having to read from the actual drives. A battery-backed or flash-based write-back cache will cache writes as well and only flush to the disks periodically. This improves overall throughput significantly.
Distributing I/O requests evenly across drives is also important. With data striping techniques used in RAID 0 and RAID 5, I/O is spread across drives. Adding more drives increases aggregate I/O bandwidth. Using hot spares and redistributing data from failed drives also helps prevent bottlenecks.
Finally, choosing the appropriate RAID level for the use case is critical. RAID 1 and RAID 10 provide better random read/write performance while RAID 5 and RAID 6 are more optimized sequential workloads and reads. Benchmarking configurations with representative workloads helps determine the optimal RAID performance.
Parity RAID vs. Erasure Coding
Parity RAID is a classic and well-known data protection scheme that has been used for decades. More advanced erasure coding schemes have emerged in recent years as an alternative approach. There are some key differences between parity RAID and erasure coding:
Parity RAID relies on a simple XOR parity calculation to protect against disk failures. Erasure coding uses more complex mathematical algorithms to spread data and parity information across a set of storage devices. This provides greater flexibility in the data-to-parity ratio. For example, with a 10 disk RAID 6 array, 2 disks are used for parity leaving 8 for data. An erasure coded system could be configured for a 20:4 data to parity ratio on the same 10 disks.
A key benefit of erasure coding is scalability. As the number of disks grows into the tens or hundreds, the overhead of dedicating full disks to parity in RAID becomes prohibitive. Erasure coding allows finer control over the parity overhead as the system scales.
However, parity RAID has the advantage of computational simplicity and standardized implementations. The mathematical calculations for erasure coding are more complex and can consume more processing resources. RAID is universally supported in operating systems and hardware RAID controllers.
In summary, erasure coding provides more flexibility whereas parity RAID offers simplicity and standardization. For large scale storage environments, erasure coding is generally viewed as a more advanced data protection scheme.
Parity RAID Challenges
Parity RAID setups, like RAID 5 or RAID 6, face some unique challenges compared to other RAID levels, specifically around array rebuilding and vulnerabilities.
When a drive fails in a parity RAID array, rebuilding the array can be very demanding on the remaining disks. All the data from the surviving drives must be read to recalculate parity and restore redundancy. This puts substantial stress on the disks and can lead to performance issues or even cascading failures during the rebuild. As drive capacities increase, rebuild times get longer and the risk of failure grows (Source).
Another issue with parity-based RAID is vulnerabilities like the RAID 5 write hole. If a drive fails during a write operation, the parity can become corrupted leading to potential data loss. Workarounds exist, but they come with performance trade-offs.
The challenges of parity-based RAID has led to increasing use of RAID 10 in the datacenter because it does not suffer the same rebuilding pains. However, RAID 10 provides less efficient storage capacity than parity RAID. There are always tradeoffs to consider when choosing a RAID level.
Conclusion
Parity refers to additional information that provides redundancy in a RAID configuration. Parity allows data to be reconstructed if one drive fails in a RAID array. By calculating and storing parity information distributed across multiple drives, RAID can survive the loss of any single drive without losing data.
RAID levels like RAID 5 and 6 rely on parity to provide fault tolerance. The trade-off is reduced storage capacity and write performance compared to a single large drive or striped RAID 0 array. But parity RAID delivers improved reliability and the ability to withstand drive failure.
In the future, we may see wider adoption of more advanced erasure coding schemes that can deliver even better storage efficiency compared to traditional parity RAID. But parity RAID remains a simple, affordable way to balance performance, capacity, and fault tolerance for many applications.
As storage devices grow in capacity, rebuilding large failed drives in parity RAID arrays becomes more challenging. We may see new hybrid RAID implementations that combine parity, caching, and auto-migration techniques to optimize large-scale RAID rebuilds and minimize risk of data loss.
But parity will likely continue playing a key role in RAID going forward. The simplicity and effectiveness of parity-based redundancy has made it a staple of RAID implementations for decades. While new RAID techniques emerge, parity RAID remains a proven, practical solution for balanced storage performance and protection.