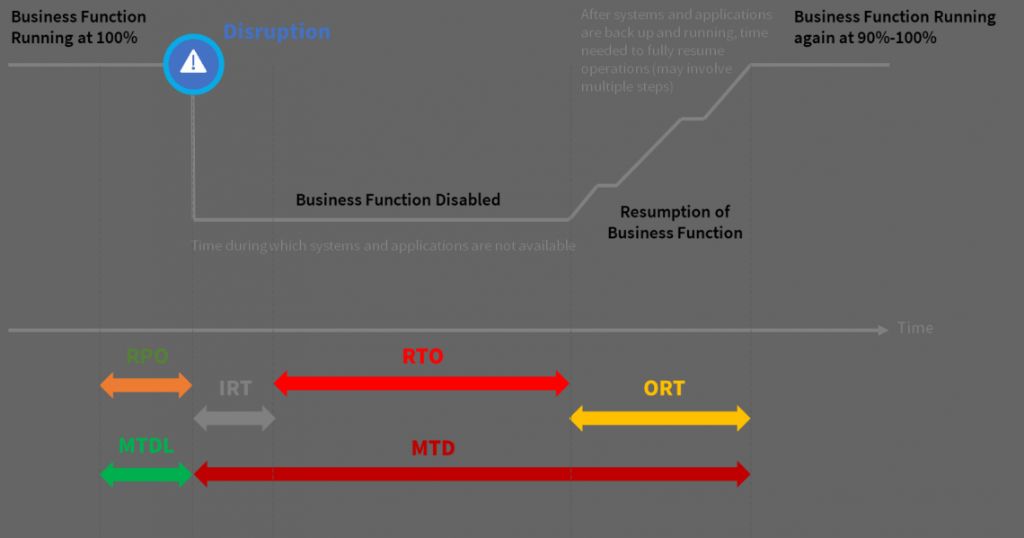
RTO (Recovery Time Objective) and RPO (Recovery Point Objective) are important concepts in disaster recovery and business continuity planning. They help organizations define recovery goals and objectives when planning for potential disruptions to IT systems and business operations.
RTO refers to the maximum tolerable length of time that a business process or service can be disrupted after a disaster. It is the duration of time within which a business must be restored after a disruption to avoid unacceptable consequences. RPO refers to the maximum tolerable period in which data might be lost due to a disruption. It is the maximum amount of data loss that is acceptable during a disruption.
Defining RTOs and RPOs is a key step in developing disaster recovery and business continuity strategies. They help set concrete targets for restoration efforts and establish metrics by which recovery capabilities can be measured. This article will provide clear explanations and examples of RTO and RPO to help readers understand these important concepts.
What is RTO?
RTO or Recovery Time Objective refers to the maximum acceptable time an organization can tolerate downtime after a business disruption. It is the duration of time within which a business process must be restored following a disaster to avoid unacceptable consequences.
RTO is usually defined in hours and minutes. For example, a 2-hour RTO means that a business process or service must be restored within 2 hours after a disruption. Defining RTOs for critical business processes and services helps to set concrete restoration targets and priorities. It also guides investments in solutions to meet these targets.
Some key things to note about RTO:
– RTO begins when the disruption first occurs, not when detection or recovery efforts begin. This accounts for any lag in detecting and responding to failures.
– RTO applies to business processes and services, not just the underlying infrastructure. The focus is on overall business function restoration.
– RTOs are tailored to the unique needs of each business process or service. More critical services get shorter RTOs. Less critical operations can have longer ones.
– Executives and business process owners are involved in setting RTOs. They determine the maximum downtime acceptable based on financial, reputational and other risks.
– Technical staff use defined RTOs to design disaster recovery solutions like backups, redundancies and failover capabilities. The solutions are designed to meet RTO requirements.
– RTOs drive priorities for restoration. Services with shorter RTOs receive priority in recovery efforts.
Examples of RTOs
– Payment processing: 1 hour
– Ecommerce website: 1 hour
– Call center: 2 hours
– Email service: 4 hours
– HR payroll system: 24 hours
– Business analytics system: 72 hours
As illustrated in these examples, RTOs are shorter for essential revenue-generating services and customer-facing systems. Backend systems can often sustain longer downtime without severe consequences.
What is RPO?
RPO or Recovery Point Objective refers to the maximum tolerable period of time in which data might be lost due to a disaster. It is the maximum duration of time for which data can be lost when service is restored after an outage.
RPO is typically defined in hours, minutes or seconds. It establishes a point of data recovery that a business must revert back to during system restoration. RPOs help set concrete data loss targets.
Some key points about RPOs:
– RPO represents the oldest data that is acceptable for restored systems. Data more recent than the RPO may be lost.
– RPO sets data loss limits. Backup and replication solutions are designed to meet RPOs.
– RPO is not the actual data loss. It is the maximum data loss set as an acceptable objective.
– RPO applies to application data like databases, not just backups. It factors in data replication methods.
– Tighter RPOs require infrastructure like continuous data mirroring that comes at higher cost.
– As with RTOs, RPOs are tailored to the specific needs of business systems and processes.
Examples of RPOs
– Billing system database: 1 hour RPO
– ERP transaction data: 15 minute RPO
– Email system: 1 day RPO
– File shares: 1 week RPO
– Archive data: 1 month RPO
Business-critical systems usually have tighter RPOs of minutes or hours. Systems with less critical data can sustain longer RPOs of days or weeks.
Differences Between RTO and RPO
RTO and RPO are related but distinct disaster recovery concepts:
RTO
– Refers to overall service and function restoration
– Measured in hours and minutes
– Defines the duration of acceptable downtime
RPO
– Focuses on data loss limits
– Measured in hours, minutes or seconds
– Defines the point of data recovery
While RTO is concerned with service availability, RPO is concerned with data loss. RTO begins at the start of an outage. RPO measures backwards from when service is restored.
RTO and RPO may interact and influence one another. A shorter RTO requirement may necessitate a shorter RPO as well to restore normal operations more quickly. But optimal RTO/RPO alignment depends on the unique needs of each business system.
Setting Appropriate RTOs and RPOs
Appropriately defining RTOs and RPOs is critical for effective disaster recovery planning and business continuity. Here are some guidelines for setting suitable objectives:
– Involve the right stakeholders – Include business managers, process owners and IT leaders to set objectives tailored to business needs.
– Conduct business impact analysis – Analyze potential financial, reputational and productivity impacts of downtime. Use this data to help define objectives.
– Prioritize systems and processes – Set tiered RTOs/RPOs based on service criticality. Align DR investments to priority.
– Evaluate capabilities and costs – Consider current capabilities and weigh investments needed to meet defined objectives. Adjust as needed based on cost-benefit analysis.
– Review periodically – Revalidate defined RTOs/RPOs as business needs evolve to ensure continued alignment.
– Test and audit – Perform tests and audits to ensure defined objectives are met and remain achievable. Update if needed.
Properly set and aligned RTOs/RPOs provide measurable DR targets tailored to business needs and capabilities. They are the foundation for effective disaster recovery.
Why RTO and RPO are Important
Defining RTO and RPO is important for these key reasons:
– Sets concrete restoration targets – Establishes quantifiable goals for recovery efforts and accountability.
– Quantifies acceptable downtime – Defines maximum tolerable outage duration based on business impact.
– Limits data loss – Sets data recovery point to curb potential data loss to acceptable levels.
– Guides DR investments – Aligns DR, BC and resilience solutions to meet established RTO/RPO goals.
– Prioritizes recovery – Focuses resources on restoring essential services and systems first based on tighter RTO/RPO.
– Provides metrics – Creates measurable standards to benchmark recovery capabilities against goals.
– Fulfills compliance – Helps meet regulatory compliance requirements related to DR planning and resilience.
– Reduces risk – Minimizes financial, productivity and reputational risks from outages by restoring operations quickly and with minimal data loss.
RTO and RPO are core elements of a disaster recovery plan and business continuity strategy. Defining and aligning them to business needs is essential for resilience.
Best Practices for Defining RTOs and RPOs
Here are some best practices for defining suitable RTOs and RPOs:
– Focus on business impact – Set RTOs/RPOs based on financial and operational consequences of downtime. Don’t default to technical capabilities.
– Involve business stakeholders – Get input from business managers on what RTOs/RPOs adequately meet their needs.
– Classify criticality tiers – Group services and systems into different tiers. Set tiered RTO/RPO standards accordingly.
– Consider dependencies – Account for interdependent systems and upstream/downstream impacts in setting objectives.
– Factor in peak periods – Define objectives to meet needs even during busy seasons and maximum processing volumes.
– Build in buffers – Leave room for inevitable human delays and uncertainties in recovery execution.
– Reevaluate periodically – Review defined RTOs/RPOs at least annually as business needs evolve.
– Assess capabilities – Validate that current DR/BC capabilities can meet defined objectives or identify gaps.
– Test regularly – Conduct tests to ensure RTO/RPO standards are met consistently as validated proof points.
Well-defined RTOs and RPOs tailored to business needs are vital for effective disaster recovery and business continuity. They provide measurable targets to plan towards and validate against.
How to Calculate and Report on RTO and RPO
Measuring and reporting on RTOs and RPOs provides important metrics to gauge disaster recovery capabilities. Here are key steps:
Calculate RTO:
– Identify start of outage – First failure or disruption event.
– Mark service restoration – Time when service is restored or recovered.
– Subtract outage start from restoration complete time.
– Compare to RTO objective.
Calculate RPO:
– Determine outage start time – When failure or disruption occurred.
– Identify recovery point – Time of most recent available backup or replicated data.
– Subtract recovery point time from outage start time.
– Compare result to RPO objective.
Report on RTO/RPO:
– Track and document RTO/RPO for each disruption.
– Identify violations – Events exceeding defined RTO/RPO objectives.
– Analyze trends – Identify recurring issues contributing to violations.
– Present metrics to stakeholders – Report on RTO/RPO performance.
– Identify gaps and improvements – Use results to justify DR investments and process improvements.
Performing RTO/RPO calculations and analyses provides tangible metrics to demonstrate disaster recovery capabilities. Results can be used to identify gaps, secure funding, and strengthen overall resilience.
How to Improve RTO and RPO
There are various ways organizations can improve RTO and RPO capabilities:
Enhance detection:
– Implement monitoring tools – For early problem identification.
– Create alerting thresholds – For proactive notifications.
– Perform log analysis – To identify failure patterns.
Streamline recovery processes:
– Document procedures – Detail steps for smooth restoration.
– Automate where possible – Reduce manual errors and delays.
– Integrate tools – For coordinated workflows.
– Validate periodically – Through testing and rehearsals.
Strengthen infrastructure redundancy:
– Replicate data – For recovery point flexibility.
– Failover capabilities – Automated switching to isolate failures.
– Backup power – To run equipment during power outages.
– Alternate sites – To restore service rapidly.
Review solutions:
– Evaluate capabilities – Identify gaps in meeting RTO/RPO objectives.
– Explore new solutions – Purpose-built disaster recovery and data protection technologies.
– Conduct cost-benefit analysis – Prioritize solutions for maximum benefit.
Refine RTO/RPO definitions:
– Consider acceptable risks – Balancing business needs with solution costs.
– Set tiered standards – Custom RTO/RPO by system/process criticality.
– Allow for future growth – Account for potential future capacity needs.
Aligned to business needs and resilience requirements, optimal RTOs and RPOs provide attainable targets for disaster recovery.
Example Scenarios
Here are example scenarios illustrating RTO and RPO in practice:
Online Retail Website
ABC Online Retail has an ecommerce website with the following RTO and RPO definitions:
RTO: 1 hour
RPO: 5 minutes
The website experiences a 90-minute outage. When service is restored, the most recent available data backup is from 30 minutes prior to the failure.
RTO – Website restored after 90 minutes, exceeding 1-hour RTO standard
RPO – Website recovered with 30 minutes potential data loss, within 5-minute RPO
This scenario highlights an RTO violation but successful RPO. The company may need to improve its restoration protocols to meet the 1-hour website RTO.
Hospital Clinical Information System
A hospital sets these RTO/RPO goals for its critical patient management system:
RTO: 4 hours
RPO: 1 hour
The system suffers a hardware failure causing 6 hours of downtime. Restoration uses replicated data from 2 hours prior to the failure.
RTO – System restored after 6 hours, missing 4-hour RTO
RPO – Recovery data within 1-hour RPO goal
This example shows an RTO failure but met RPO. The hospital may choose to invest in standby hardware redundancy to prevent extended outages.
Financial Reporting System
A financial firm sets RTO and RPO as:
RTO: 48 hours
RPO: 24 hours
A cyberattack disrupts their financial system for 60 hours. Backups from 10 hours before the attack are used to restore service.
RTO – Systems recovered after 60 hours, exceeding 48-hour RTO
RPO – Data recovered within 24-hour RPO policy
For this business-critical system, both the RTO and RPO may need to be reviewed given the long disruption and data loss. Improved security and data replication may be warranted.
These examples illustrate how RTOs and RPOs provide measurable metrics to evaluate real-world events against DR objectives. The results can drive planning improvements.
Key Takeaways
– RTO determines maximum acceptable time that a process or service can be down. RPO defines maximum potential data loss.
– RTO focuses on service restoration duration. RPO focuses on data recovery point.
– RTOs and RPOs must align to business needs based on impact of downtime.
– Stringent RTOs and RPOs require greater investment in resilience solutions.
– Metrics are critical for evaluating capabilities against objectives and identifying gaps.
– Regular testing and reviews ensure RTO/RPO standards remain current and achievable.
Conclusion
Defining RTOs and RPOs tailored to business needs provides concrete disaster recovery targets and guides resilience planning. Monitoring and reporting on RTO/RPO performance is crucial for validating capabilities and identifying improvement opportunities. With appropriate RTOs and RPOs aligned to recovery priorities and acceptable risks, organizations can build robust continuity programs to minimize disruptions and data loss from inevitable outages.