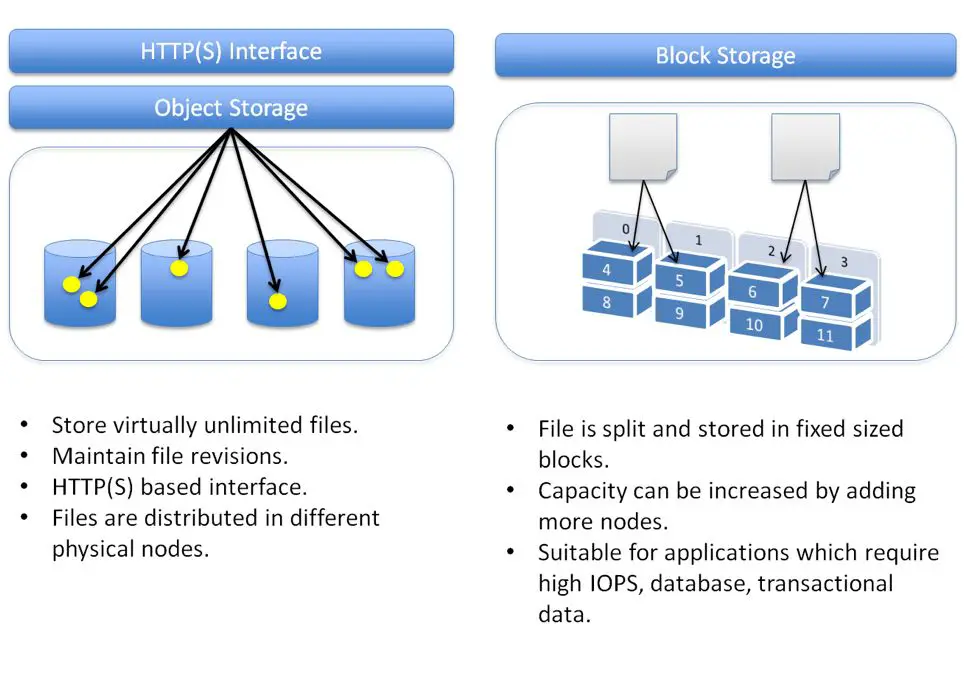
Block based storage and object based storage are two different approaches for storing data in the cloud. Both have their own set of advantages and use cases. Choosing between block and object storage depends on the specific needs of the application or workload.
Quick Answers
Here are some quick answers to common questions about block storage versus object storage:
- Block storage provides raw, low-level access to storage devices. Object storage manages data as objects with metadata.
- Block storage offers high performance for transactional workloads. Object storage is better for large amounts of unstructured data.
- Block storage allows random read/writes to any location. Object storage requires accessing the full object.
- Block storage requires managing storage at the disk/volume level. Object storage is highly scalable and abstracts storage management.
- Block storage suits latency-sensitive workloads like databases. Object storage suits throughput-intensive workloads.
Block Storage Overview
Block storage provides access to raw block-level storage devices like volumes, disks, and partitions. With block storage, the cloud provider virtualizes the physical storage infrastructure into volumes/disks for consumption. The virtualized storage appears as a local disk drive to workloads running in the cloud.
Block storage allows writing data to any part of the virtual disk. Applications can read and write data at the byte level to precise block locations. This makes block storage very performant for transactional workloads that require frequent, low-latency random I/O. Example workloads well-suited for block storage include databases, enterprise applications, and filesystems.
The key advantages of block storage are:
- Low latency and high throughput random read/writes
- Consistency in performance
- Direct access to specific data blocks
- Supports in-place updates and modifications
- Integrates with compute instances like a local drive
- Snapshots for backups and restores
Common block storage services offered by cloud providers include Amazon Elastic Block Store (EBS), Azure Disk Storage, and Google Persistent Disk.
Object Storage Overview
Object storage manages data as objects in a flat namespace. An object includes the data, metadata, and a globally unique identifier. Object storage assigns a unique key to each object for retrieval.
The simplicity of accessing data via a unique key enables object storage systems to scale easily. Object storage can grow to exabyte scale while still delivering high throughput. The flat structure makes it easy to run parallel queries across petabytes of data.
Object storage works well for storing large amounts of unstructured data like images, videos, backups, archives, and file data. Example workloads suitable for object storage include cloud applications, content distribution, and big data analytics.
The key advantages of object storage are:
- Scalability to billions of objects
- Durability and high availability
- Metadata tagging and queries
- Global data access and distribution
- Versioning
- Lifecycle management policies
Prominent object storage services include Amazon S3, Azure Blob Storage, and Google Cloud Storage.
Block Storage vs. Object Storage
Some key differences between block and object storage:
| Block Storage | Object Storage |
|---|---|
| Provides raw block-level access to volumes/disks | Manages data as objects with metadata |
| Supports random writes | Suited for sequential access |
| Works well for transactional and latency-sensitive applications | Ideal for storing large amounts of file and object data |
| Limited scalability, requires management at the volume level | Highly scalable to billions of objects |
| Strong consistency and immediate updates | Eventual consistency due to replication |
| Integrates with compute instances like a disk drive | Accessible over HTTP via REST APIs |
Performance
Block storage delivers higher performance for workloads requiring frequent, fast random reads and writes. The ability to directly read/write specific blocks enables low-latency access. Performance remains consistent even as storage volumes grow in size.
Object storage does not support random writes. Data needs to be overwritten or appended sequentially to an object. Accessing data requires retrieving the entire object. However, object storage achieves high aggregate throughput for large volumes of data by spreading work across many servers and drives.
Access Methods
Block storage attaches to compute instances similarly to a local drive. It enables direct read/write access to storage blocks via the OS. This makes it ideal for hosting transactional databases, filesystems, and applications requiring raw block-level access.
Object storage exposes a REST API or SDK for programmatic access over HTTP/HTTPS. Accessing data involves reading or writing entire objects based on the key. The simple HTTP-based access makes object storage easy to consume from any development environment.
Scalability
Block storage scales by adding more volumes. But storage management becomes more complex at higher scales. Expanding capacity requires carving out volumes from new physical drives.
Object storage scales seamlessly to handle exponential data growth into the exabytes. The flat architecture makes it easy to expand storage clusters horizontally. Object storage abstracts the underlying physical storage, enabling unlimited expansion.
Durability and Availability
Block storage relies on redundancy mechanisms like RAID and replication for durability. But hardware failures can still lead to data loss if backups are inadequate.
Object storage replicates objects across multiple facilities and servers. Data is versioned and protected against hardware failures, deletions, and corruption. Object storage offers 11+ nines of durability over a given year.
Metadata
Block storage has no innate metadata capabilities. Filesystems built on block storage provide metadata and structure.
Object storage associates customizable metadata like tags, headers, and properties with each object. This enables new use cases like metadata-based searches, automation via metadata queries, and simplified data organization.
When to Use Block Storage
Use block storage for applications with these characteristics:
- Require low-latency, high-performance random I/O
- Need raw block-level access without a filesystem
- Require strong consistency and transactional semantics
- Write data in random locations instead of sequentially
- Need to expand storage capacity in small increments
- Require backups via efficient snapshots and clones
Example workloads suitable for block storage:
- Relational databases
- NoSQL databases
- Transactional applications
- Frequent random updates to data
- Boot volumes
- Real-time analytics
When to Use Object Storage
Use object storage for applications with these characteristics:
- Need to scale to massive capacities economically
- Have large amounts of unstructured data like video, images
- Write data sequentially instead of random I/O
- Require metadata tagging and querying capabilities
- Need geographically distributed and durable data
- Require lifecycle policies for managing data tiers
Example workloads suitable for object storage:
- Cloud applications
- Content repositories
- Data lakes
- Media storage and streaming
- Backups and archives
- Static web content
- Big data analytics
Using Block and Object Storage Together
In many cases, a combination of block and object storage works best. Here are some examples of using both technologies together:
- Store frequently accessed data on low-latency block storage while moving infrequently used data to cheaper object storage.
- Use block storage for databases and object storage for backups and archives.
- Serve static web content from durable, scalable object storage while keeping web applications on block storage.
- Storing raw incoming data in highly scalable object storage while processing it via block storage for analytics.
Using both block and object storage allows optimizing storage for cost and performance. The strengths of each storage type can complement the other in a multi-tier storage strategy.
Conclusion
Block storage delivers high-performance random I/O while object storage cost-effectively scales to massive capacities. Block storage suits transactional and latency-sensitive workloads. Object storage suits throughput-intensive workloads and cheaply storing vast amounts of data.
Most real-world storage needs are best served by thoughtfully combining block and object storage. The strengths of each technology are complementary. By using both block and object storage, enterprises can build flexible, scalable, and cost-effective storage infrastructure.