Virtualization refers to creating virtual versions of computing resources, such as servers, storage devices, networks and even operating systems where the framework divides the resource into one or more execution environments. The two main types of virtualization are block virtualization and file virtualization.
Block virtualization abstracts away physical storage and presents it to the operating system as virtual disk blocks that can be grouped into virtual disks. File virtualization abstracts physical storage and presents it as a file system that can be accessed using standard file access protocols like NFS and SMB.
The goal of this article is to compare block virtualization and file virtualization, examining the key differences, use cases and benefits of each approach.
Definition of Block Virtualization
Block virtualization consolidates the physical storage from multiple storage devices into what appears to be a single, logical storage device. It operates at the block layer of the storage stack, virtualizing full storage blocks rather than files or file systems. With block virtualization, the virtualization software abstracts away and hides the actual details of the underlying physical storage devices and presents a pool of logical blocks to the operating system (1).
This approach enables the creation of logical volumes or LUNs composed of storage capacity from different devices. Block virtualization provides flexibility to efficiently allocate storage blocks as needed without worrying about physical restrictions. It also facilitates operations like snapshots, replication and migration without disruption (2).
Sources:
(1) https://www.techtarget.com/searchstorage/definition/storage-virtualization
(2) https://www.techtarget.com/searchstorage/tip/Block-level-storage-virtualization-Reasons-to-implement-it
Uses and Benefits of Block Virtualization
Block virtualization provides several key benefits to organizations, including:
Consolidation
Block virtualization allows organizations to consolidate storage into unified pools or arrays, reducing the number of physical storage devices needed. This saves on costs for hardware acquisition, maintenance, power, cooling, and data center space (ServerWatch, 2023).
Increased utilization
By pooling storage capacity, block virtualization enables higher utilization rates across the consolidated storage. Organizations can avoid stranding capacity on isolated storage islands and get more out of their storage investments (ServerWatch, 2023).
Flexibility
Block virtualization abstracts the logical storage from the physical devices. This gives organizations the flexibility to add, upgrade, migrate, and rebalance storage non-disruptively without impacting applications or users (TechTarget, 2012).
Overall, block virtualization streamlines storage management, reduces costs, and provides agility to dynamically align storage with business needs.
Examples of Block Virtualization
Some of the most popular platforms for block virtualization include:
-
VMware vSphere – VMware’s flagship virtualization platform that provides a powerful, flexible and secure foundation for business agility. vSphere transforms data centers into aggregated computing infrastructures that include CPU, storage and networking resources. It enables enterprises to run business-critical applications with confidence across private, public and hybrid clouds. Leading organizations worldwide rely on VMware’s virtualization software to simplify their IT operations.
-
Microsoft Hyper-V – A native hypervisor-based virtualization product developed by Microsoft for the Windows NT family of operating systems. It creates virtual machines on x86-64 systems running Windows and allows users to run multiple operating systems concurrently. Hyper-V provides high scalability, live migration, and dynamic memory for virtual machines. It comes standard with Windows Server operating systems.
-
KVM (Kernel-based Virtual Machine) – An open source virtualization module in the Linux kernel that allows the kernel to function as a hypervisor. It can run multiple virtual machines running unmodified Linux or Windows images. As a native hypervisor, KVM offers high performance and utilizes hardware extensions for virtualization. It is a core part of major cloud platforms like OpenStack.
Definition of File Virtualization
File virtualization is a storage virtualization technology that creates an abstraction layer between the file server and end users. It involves combining multiple isolated storage devices into a single logical pool of storage space (Wikipedia, 2022). The key idea behind file virtualization is to separate the logical view of files and directories from their physical locations on storage hardware. This allows files that reside on different servers and storage devices to appear as though they are all located in the same centralized place. Users simply access a single namespace or filesystem rather than having to consider the physical environment.
In essence, file virtualization hides the complexity of distributed storage from users and applications. It provides a single point of access that allows users to work with abstract logical files and directories without worrying about where the data is physically stored. The location and underlying hardware becomes completely transparent. This improves usability, accessibility and mobility of file data across the enterprise (Techopedia, 2011).
Uses and Benefits of File Virtualization
File virtualization provides many benefits, including increased flexibility, availability, and scalability. With file virtualization, files are abstracted from their physical storage location, allowing them to be accessed from any location and aggregated from multiple sources (ServerWatch). Some key benefits of file virtualization include:
Increased flexibility – File virtualization allows files to be accessed independently of their physical storage location. Users and applications can access files without needing to know their specific location (IBM). This makes it easy to migrate files to different servers or storage devices without disrupting access.
Improved availability – By aggregating files from multiple locations, file virtualization eliminates single points of failure. If one file server goes down, the files can still be accessed from alternate locations. This increases overall uptime and availability.
Enhanced scalability – With file virtualization, it’s easy to scale storage capacity by simply adding new physical devices. The file system expands seamlessly to users and applications. Additional storage can be added without downtime or reconfiguration.
Overall, file virtualization brings more flexibility, resilience and scalability to file infrastructures. By abstracting files from physical storage, organizations gain more agility and reliability in accessing critical file-based data.
Examples of File Virtualization
Some key providers of file virtualization solutions include Nasuni, Panzura, and Ctera. These companies aim to abstract network file systems and make file storage available across locations and devices. Their solutions help consolidate file servers, while still allowing local file access.
Nasuni offers a cloud-native global file system designed to replace traditional network-attached storage (NAS) and file server silos. Its solution combines on-premises virtual storage hardware with cloud object storage. This allows for features like unlimited scalability, built-in backup, and global file sharing. According to Enterprise Storage Forum, Nasuni is known for its flexibility and hybrid capabilities.
Panzura focuses on unifying unstructured data across the enterprise through its global file system technology and cloud storage. Its solution aims to consolidate file servers and silos. ServerWatch highlights Panzura for its ability to maintain local performance while leveraging the economics, scale, and durability of the cloud.
Ctera offers a software-defined global file services platform enabling secure access to file storage from any device or location. Its Ctera Enterprise File Services Platform converges file sharing protocols, while providing a global namespace. According to TrustRadius, Ctera stands out for its seamless integration, performance, and reliability.
Key Differences
One of the major differences between block and file virtualization is the level at which they operate:
- Block level virtualization works at the disk or volume level, interacting with virtual hard disks rather than files or file systems. It operates at a low level, managing blocks of data storage.[1]
- File level virtualization works at the file system or file level. It allows multiple servers to access shared files and folders, operating at a higher level of abstraction.[2]
Due to these differences in levels of abstraction:
- Block virtualization is able to provide full virtualization for VMs or servers. It abstracts the entire storage system into virtual disks.
- File virtualization provides shared storage virtualization. It enables multiple systems to access the same files and folders, rather than having dedicated storage per system.[3]
In summary, block operates at the disk/volume level to enable full server/VM virtualization, while file operates at the file system/file level for shared storage virtualization.
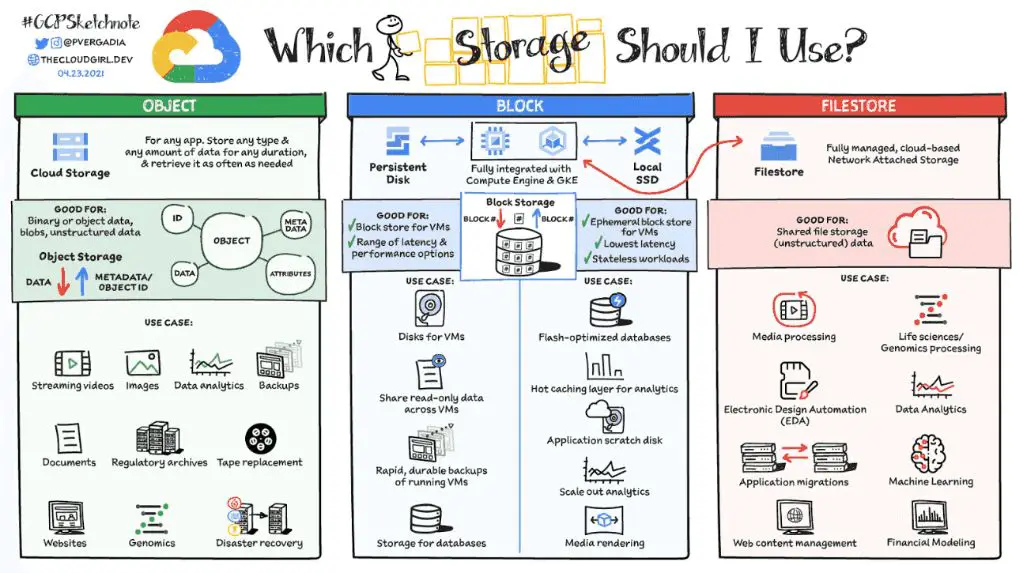
Use Cases
Block virtualization is commonly used for databases, email servers, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and other mission-critical applications that demand high performance and availability. The main use cases are:
- Database servers like Oracle, MySQL, and Microsoft SQL Server benefit from the high IOPS and low latency of block virtualization.
- Microsoft Exchange email servers are optimized on block storage to deliver fast performance.
- Block virtualization helps consolidate multiple SAN arrays into a shared storage pool for high scalability.
- Critical applications gain high availability and redundancy from block virtualization.
In contrast, file virtualization is more commonly used for:
- File servers and network-attached storage (NAS) hosting user files and shared folders.
- Big data analytics that access large datasets on HDFS or object storage.
- Media assets for video editing and content production workflows.
- Archival and backup storage with its high capacity scalability.
The key differences come down to block optimized for transactional data and performance versus file for throughput and capacity. Understanding the use cases and workload patterns help determine which virtualization approach to implement.
Conclusion
In summary, block virtualization abstracts away physical storage and presents it as logical blocks to the operating system. It is well suited for scenarios requiring flexibility, scalability, and centralized storage management. File virtualization abstracts file systems from clients and provides a global namespace. It excels at reducing data duplication, enhancing collaboration, and simplifying file migrations.
For typical virtual machine deployments, block virtualization is recommended to take advantage of dynamic provisioning and reduce storage costs. For distributed teams sharing files across locations, file virtualization facilitates secure access and synchronization. When implementing a VDI environment, both block and file virtualization together provide optimal performance and manageability. Weighing the tradeoffs between block and file virtualization for your specific use case is key to selecting the right approach.