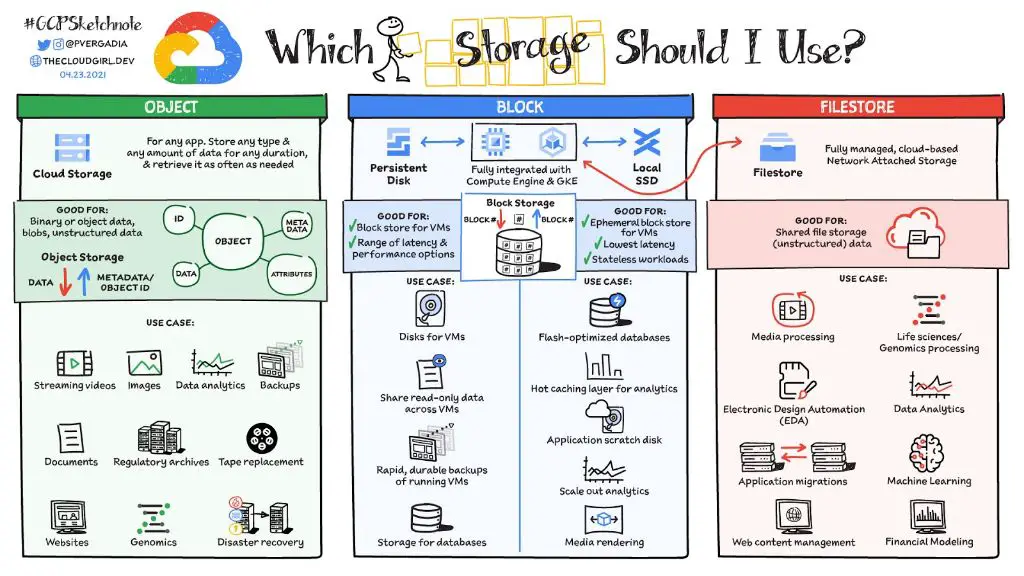
Kubernetes provides different storage options for managing application data, including block storage and file storage. Choosing the right storage system is crucial for building robust and scalable applications on Kubernetes.
What is Block Storage?
Block storage divides storage into evenly sized blocks or volumes. Each block acts as an individual hard drive that can be attached to a server. Kubernetes supports multiple block storage solutions, including:
- AWS Elastic Block Store (EBS)
- Azure Disk
- Google Compute Engine Persistent Disk
- OpenStack Cinder
In Kubernetes, block storage volumes can be provisioned dynamically through PersistentVolumeClaims. This allows storage to be allocated on demand without manual intervention. Kubernetes handles attaching and detaching block devices to nodes seamlessly.
Some key characteristics of block storage:
- Block storage is accessed directly by the operating system as a raw block device.
- Blocks can be replicated for data redundancy.
- I/O performance is excellent since data is stored contiguously.
- Volumes can be resized by adding or removing blocks.
- Block storage is ideal for databases, transactional systems, and applications needing raw storage access.
What is File Storage?
File storage organizes data in a hierarchical structure as files and folders. This is the traditional storage model used by many applications. Kubernetes supports several file storage solutions, including:
- NFS
- CephFS
- GlusterFS
- Azure File Storage
- AWS Elastic File System (EFS)
As with block storage, Kubernetes can dynamically provision file storage using PersistentVolumeClaims. The Kubernetes StorageClass API enables different classes of storage to be defined based on performance needs.
Key characteristics of file storage:
- Applications access data through the standard file/folder abstraction.
- File metadata makes it easy to organize data.
- Sharing data between containers is simple using mounted storage.
- Expanding storage just requires provisioning larger volumes.
- Better suited for apps needing shared file access rather than high performance.
Key Differences Between Block and File Storage
While both provide persistent storage for Kubernetes, block and file storage differ in some important ways:
| Block Storage | File Storage |
|---|---|
| Presented to nodes as raw block devices (no filesystem) | Uses standard file/folder abstraction |
| Mounted per pod | Can be mounted by multiple pods |
| Faster performance for transactional data | Better for shared file access |
| Volumes accessed directly by OS | Files accessed through filesystem |
| Hard to share between pods | Easier to share using mounted volumes |
In summary, block storage is best for performance-sensitive applications like databases, while file storage is better suited for sharing data between containers. File storage also simplifies storage management through standard filesystem operations.
Using Block Storage in Kubernetes
Here is an overview of using block storage with Kubernetes:
- Create a PersistentVolumeClaim (PVC) specifying the desired storage class and capacity.
- The Kubernetes control plane will provision a PersistentVolume (PV) to match the claim.
- Mount the PVC in a pod definition.
- Kubernetes will bind the PV to the PVC and attach the underlying storage device to the node running the pod.
- The application can read/write data to the block device using standard OS interfaces.
- When the pod is deleted, Kubernetes will detach and release the PV.
A simple PVC definition might look like:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-pv-claim
spec:
storageClassName: gp2
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
This allocates a 10GB volume from the “gp2” storage class. That storage can then be mounted on pods:
volumes:
- name: postgres-storage
persistentVolumeClaim:
claimName: postgres-pv-claim
Now the application running in the pod can access the block device directly for fast, low-level storage operations.
Dynamic Provisioning
Kubernetes supports dynamic provisioning of block storage using StorageClasses. This automates the creation of new PVs to match PVCs. For example, the following StorageClass for GCE PD will create SSD volumes:
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: fast-storage provisioner: kubernetes.io/gce-pd parameters: type: pd-ssd
The Kubernetes API will monitor PVCs and automatically create PVs using the specified provisioner when no matching PVs exist. This simplifies storage management and automates provisioning.
Access Modes
Kubernetes allows controlling how PVs can be accessed using access modes. Important modes for block storage include:
- ReadWriteOnce – The volume can be mounted as read-write by a single node.
- ReadOnlyMany – The volume can be mounted read-only by many nodes simultaneously.
- ReadWriteMany – The volume can be mounted for read-write access by many nodes.
Choosing the appropriate mode is important for determining how storage can be consumed. For distributed block storage, ReadWriteMany is commonly used.
Using File Storage in Kubernetes
File storage can also be consumed through PersistentVolumes in Kubernetes. The main differences are:
- Storage is presented to pods as a mounted file system instead of a raw block device.
- StorageCapacity is defined in gigabytes rather than separate namespaces for block storage.
- Access modes determine read-write capabilities at the filesystem level.
For example, here is a PVC for a NFS share:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: nfs
resources:
requests:
storage: 1Gi
The NFS storage can then be mounted on multiple pods:
volumes:
- name: nfs-storage
persistentVolumeClaim:
claimName: nfs-pvc
All containers in those pods will have read-write access to the same shared filesystem. This makes sharing data between pods simple.
ReadWriteMany Access
One key advantage of file storage is the ability to mount volumes using ReadWriteMany access. This allows simulatenous read-write access from multiple nodes. Many traditional block storage solutions only support ReadWriteOnce.
File storage that supports ReadWriteMany includes:
- NFS
- CephFS
- GlusterFS
- Azure File Storage
- AWS Elastic File System (EFS)
This makes shared file access simple and provides concurrent read-write capabilities for entire storage volumes. Multiple pods can read and write the same files without copying data between volumes.
Expanding Volumes
Another advantage of file storage is the ability to easily expand storage capacity. For block storage, expanding a volume requires manually allocating additional blocks and it may require downtime.
With file storage, admins can simply allocate larger PersistentVolumeClaims to expand the available filesystem space. For example:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: nfs
resources:
requests:
storage: 5Gi (increased from 1Gi)
After resizing the PVC, the underlying NFS share will be expanded without disrupting running pods using that volume. This simplifies expanding storage as needed.
Performance Considerations
Storage performance is crucial for many applications. There are some key factors to consider when evaluating block vs file storage:
- Block storage offers higher performance for transactional workloads. The raw disk access enables faster, consistent I/O.
- File storage has slower baseline I/O due to the overhead of filesystem abstraction. But it scales well for high throughput workloads.
- File storage can suffer from inconsistent performance due to filesystem fragmentation issues over time.
- Both block and file storage performance depend heavily on the underlying hardware. High-end NVMe SSD storage offers faster performance.
- Distributed block and file storage solutions (like Ceph) can deliver excellent performance by spreading I/O across nodes.
For performance-critical systems like databases, block storage is generally the preferred option. File storage is sufficient for many general purpose workloads.
In addition to raw throughput, factors like IOPS, latency, and consistency determine real-world performance. Storage SLAs and benchmarking help identify solutions that meet application needs.
Cost Comparison
Storage pricing also varies between block and file solutions:
- Block storage is priced based on allocated capacity, IOPS, and throughput. It can be more costly at equivalent performance levels.
- File storage pricing is typically based only on allocated capacity. It provides lower cost for lower performance requirements.
- With block storage, you only pay for allocated volumes. File storage means paying for the entire filesystem provisioned.
- Both block and file storage offer tiered pricing based on performance levels. Faster SSD storage costs more than HDD.
- The use of local disks is cheaper but lacks redundancy. Replicated block/file storage improves durability.
In general, file storage on shared clusters offers better storage density at lower costs. But block storage is frequently required to meet performance SLAs.
Use Cases
Some common use cases where block or file storage excel include:
Block Storage Use Cases
- Databases
- Transactional processing
- Systems needing raw disk access
- Application boot disks
- Low-latency access to storage
- Centralized storage pools for clusters
File Storage Use Cases
- Serving shared files like media and documents
- Big data analytics
- Log processing
- Content management
- Archival storage
- Shared access across multiple pods
The specific application requirements determine if block or file storage makes the most sense. Optimizing for performance and cost is key.
Conclusion
Kubernetes provides great flexibility for consuming both block and file storage. Block storage offers high performance for transactional data. File storage simplifies sharing data across pods. The right solution depends on application needs:
- Choose block storage when you need raw performance and disk access.
- Leverage file storage for shared file access and easier management.
- Combine both block and file storage across applications for a robust storage environment.
- Utilize dynamic provisioning to reduce storage management overhead.
- Take advantage of provider-specific storage features for enterprise needs.
As you build applications on Kubernetes, consider how data will be accessed across microservices. The optimal storage infrastructure ties into application architecture and data flow. With the flexibility of Kubernetes, you can mix and match storage solutions to meet the needs of each workload.