Backups are an essential part of any data management strategy. Making regular copies of data provides protection against data loss from hardware failure, accidental deletion, malware, and other threats (USGS). Whether for personal files or business-critical systems, having backups ensures valuable data can be recovered in the event of an unexpected problem (NetApp).
There are different types of backup strategies that vary in how frequently they run and how much data they copy. Understanding the differences can help choose the right approach for particular use cases and requirements.
File-Level Backups
File-level backups, as the name implies, back up data at the file and folder level rather than the entire system or disk (Veeam, 2023). With file-level backups, users can select specific files, folders, or volumes to back up rather than having to back up everything.
Some key characteristics of file-level backups:
- Backs up files and folders rather than full disk images
- Allows for granular restores of individual files or folders
- Usually faster than full system backups as less data needs to be copied
- Storage efficient as only designated files are backed up
- Often utilizes incremental backups to save storage space
- Backups can be scheduled as frequently as needed
In summary, file-level backups provide a flexible way to back up only your most important files and folders on a regular basis (MSP360, 2021). This saves time and storage space compared to full system image backups.
Block-Level Backups
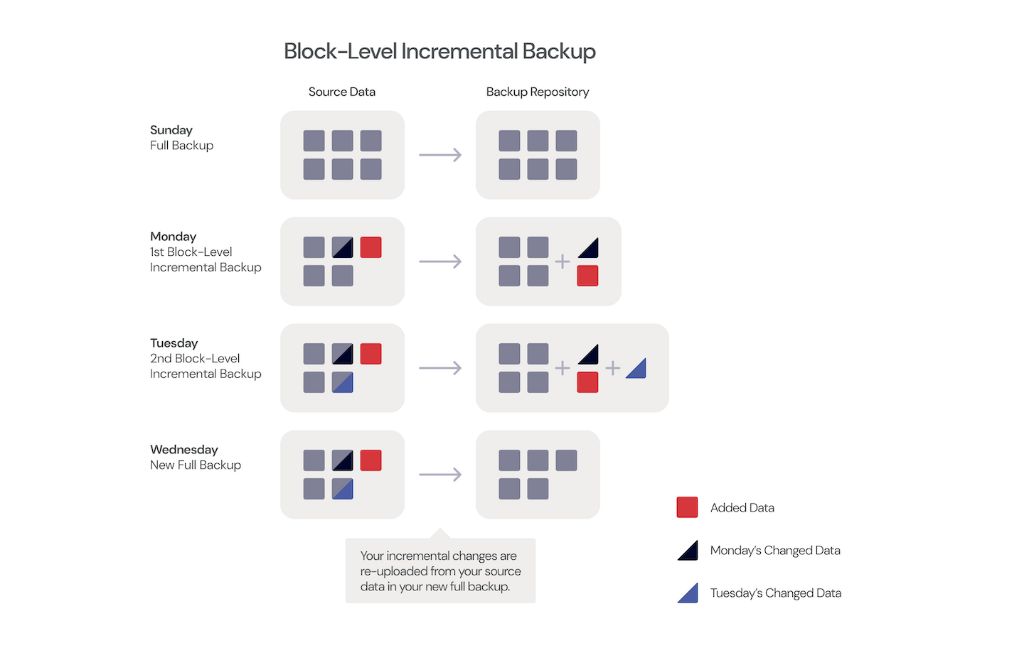
Block-level backup, also known as block-based incremental backup, backs up data in fixed-size blocks rather than whole files or folders. With block-level backup, only changed blocks are backed up, not entire files or volumes. This allows for more efficient and faster backups.
Block-level backup software like Backblaze and MSP360 divides files into equal sized blocks, generating a hash for each block. On subsequent backups, it re-calculates the hashes, comparing them to previous backups to identify changed blocks. Only changed blocks are sent to backup storage. Unchanged blocks already exist in the backup repository and are not transferred again.
This differs from file-level backup which backs up entire files whenever any part of the file changes. Block-level backup transmits less redundant data and minimizes bandwidth usage during backups.
Granularity
Granularity refers to how granular or detailed the backup is. File-level backups are more granular, backing up at the individual file level. Block-level backups are less granular, backing up in larger blocks of data. As Acronis explains, file-level backup “allows for granular recovery of individual files or folders.” With block-level backup, while you can still restore individual files, the backup process operates on the block level. This means file-level backups capture more granular detail and allow for more granular recovery.
The advantage of the increased granularity in file-level backups is that you can restore individual files easily. The downside is it takes longer to back up and requires more storage space. With block-level backups, you get faster backups and use less storage space, but you lose some granularity in terms of restore.
Speed
Block-level backups are generally much faster than file-level backups. This is because block-level backups read data at the disk block level, allowing them to backup large amounts of data very quickly without caring about individual files or the file system. According to Cloudwards, block-level backup services like IDrive and pCloud can achieve speeds of over 100 MB/s.
In contrast, file-level backups have to iterate through all the files and folders in the file system. This requires a lot more overhead, especially for backups with millions of small files. PCMag notes that file-level backup speeds often max out below 50 MB/s. So block-level backups can be 2-3x faster or more compared to traditional file-level backup methods.
For large backup sets or systems with lots of small files, the speed advantage of block-level backups makes them much more efficient. File-level backups can take hours or days to complete, whereas block-level backups can complete in minutes without compromising reliability.
Space Efficiency
Block-level backups are generally more space efficient than file-level backups. Block-level backups break files down into smaller fixed-size blocks, which allows more fine-grained deduplication and compression (Storage efficiency, 2023). This means if a portion of a file is duplicated elsewhere, only one instance of that block needs to be stored. File-level backups store an entire file each time it is backed up, even if only a small part has changed. Block-level backups avoid storing redundant data, and therefore require less storage space (Backup Performance: Solved, 2023).
In addition, block-level deduplication happens inline during the backup process, while file-level deduplication is a post-process. Inline deduplication improves efficiency by avoiding storing duplicate data in the first place (How do you measure and improve backup efficiency, 2023). The granularity of block-level backups allows them to more precisely eliminate redundancy and maximize storage savings.
Versioning
When it comes to versioning, there is a key difference between file-level and block-level backups. File-level backups typically support more granular versioning of files over time. This means that file-level backups allow you to restore previous versions of individual files as they existed at certain points in time. For example, Carbonite offers unlimited file versioning with their file-level backup service (Carbonite).
With block-level backups, versioning is generally less flexible. Often you can only restore snapshots of the entire backup at certain intervals, but not previous versions of individual files. However, some block-level backup solutions like Backblaze do provide limited file versioning capabilities (Cloudwards). Overall though, file-level backup has a clear edge when it comes to granular version control.
Restores
One key difference between file-level and block-level backup is the restore process. With file-level backups, restoring data is relatively simple. You can navigate to the specific files or folders you want to restore and recover just that data. This makes file-level backup ideal if you just need to restore a few important documents or directories (source).
Block-level backups, on the other hand, allow you to restore entire volumes or systems. The block-level approach captures everything on a disk, including the operating system, applications, settings, and all files. This enables full bare metal restores to get a system back up and running quickly. However, it also means restoring individual files or folders may be more cumbersome compared to file-level backup solutions (source).
In summary, file-level backup provides simpler, more granular restores of individual files or folders. Block-level backup enables full system restores but recovering individual data may involve extra steps.
Use Cases
When considering whether to use file-level or block-level backup, the main factors are the size and number of files, desired backup speed, and ability to restore previous versions. Here are some guidelines on when to use each:
File-level backup is preferable when:
- You have a small number of large files. Backing up fewer, larger files is faster with file-level backup.
- You need backup of open/locked files. File-level can back up open files whereas block-level cannot.
- You want to retain older versions of files. File-level makes restoring previous versions simpler.
- You have limited backup storage space. File-level only stores changed portions of files.
Block-level backup is better when:
- You have a large number of small files. Block-level backs up everything in bulk regardless of file count.
- You want faster incremental backups. Block-level identifies changed blocks efficiently.
- You have more backup storage space. Block-level duplicates unchanged data across backups.
- Point-in-time restore of a volume is critical. Block-level maintains snapshots for entire volumes.
In summary, file-level backup works best for fewer large files and block-level is optimal for many small files and entire volumes.
Conclusion
In summary, the key differences between file-level and block-level backups are:
- Granularity – file-level backups the entire file, block-level backups only changed blocks
- Speed – block-level backups are faster for large files
- Space efficiency – block-level reduces storage needs by not duplicating unchanged data
- Versioning – file-level maintains previous versions as full files, block-level uses pointers
- Restores – file-level restores whole files, block-level can restore subsets of files
For most use cases, block-level backup is recommended due to its speed and storage advantages. File-level backup can be useful for full system backups or minimal changes between versions. When choosing a backup solution, consider how it will be used and weigh the benefits of each approach. The optimal solution likely utilizes both methods to maximize restore capabilities.