RAID (Redundant Array of Independent Disks) is a technology that provides increased storage functions and reliability through redundancy. It combines multiple physical disk drives into a single logical unit to provide data redundancy, performance improvement, or both. The purpose of RAID is to protect against hardware failures by distributing data across multiple disks.
RAID is designed to prevent data loss in the event of a drive failure. By writing data across multiple disks in a redundant manner, RAID safeguards the data by allowing continued operation if one of the disks fails. The different RAID levels provide various combinations of performance, redundancy, and storage efficiency based on how data is distributed across the array.
According to Synology NAS User’s Guide, RAID provides a brief introduction to the key features and differences between each RAID type. Understanding the fundamentals of RAID technology provides the foundation for selecting the appropriate RAID level based on your specific storage needs.
What is Data Redundancy?
Data redundancy refers to the practice of storing critical data in multiple places within a storage system to protect against data loss in the event of a failure. According to TechTarget, data redundancy is “the act of storing the same data in two or more separate places within a data storage environment” (1). The main purpose of data redundancy is to prevent data loss and ensure continuity of operations if hardware fails or data becomes corrupted.
With data redundancy, if one copy of the data is compromised or unavailable, the system can failover to an alternate copy seamlessly. This helps minimize downtime and disruption. As Talend states, redundancy provides “an insurance policy against disk failure” by keeping duplicate copies (2). Techopedia explains data redundancy is “a core principle of disaster recovery planning” as it safeguards against both localized failures and catastrophic system-wide failures (3).
In summary, data redundancy refers to storing duplicate copies of critical data to prevent permanent data loss and ensure high availability in the event of hardware issues, software bugs, viruses, user errors, natural disasters or other failures.
RAID Levels
RAID (Redundant Array of Independent Disks) allows multiple disk drives to be combined together into a RAID array to provide data redundancy and/or improve performance. There are several standard RAID levels that provide different combinations of increased data reliability and/or increased input/output performance. The most common RAID levels are:
RAID 0 – Disk striping without parity or mirroring. RAID 0 provides high performance but no redundancy. Data is striped across multiple disks for high throughput, especially for large files, but if one drive fails all data will be lost.[1]
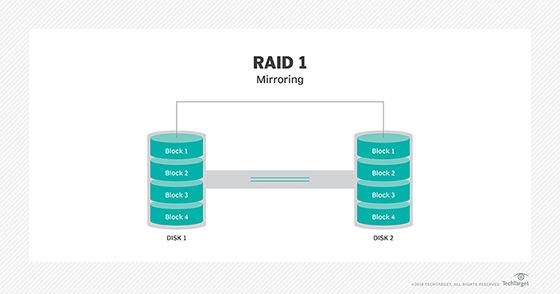
RAID 1 – Disk mirroring without parity or striping. Provides 100% redundancy by writing identical data to pairs of drives, but does not improve performance. If one drive fails, the other contains an exact copy of the data.
RAID 5 – Block-level striping with distributed parity. RAID 5 provides fault tolerance using parity data distributed across all drives. Can survive one drive failure without data loss but write performance is degraded.
RAID 6 – Block-level striping with double distributed parity. RAID 6 provides fault tolerance using dual parity to survive up to two drive failures with no data loss but requires more disk overhead for parity storage.
There are additional RAID levels (RAID 10, 50, 60) that are nested or hybrid RAID levels combining features of the standard levels above.
How RAID 1 Provides Redundancy
RAID 1, also known as disk mirroring, provides data redundancy by writing duplicate copies of data to paired drives (Source). This mirroring ensures that if one drive fails, an identical copy of the data still exists on the second drive. RAID 1 operates by receiving data from the host, calculating a checksum for error checking, then simultaneously writing the data to two separate drives. This duplication provides high fault tolerance and allows the array to survive a single drive failure without data loss or system downtime. However, RAID 1 duplication results in 50% storage efficiency since the available capacity is essentially cut in half. The benefit is extremely high data reliability and integrity due to the mirrored copies. Overall, the core value of RAID 1 is high redundancy through disk mirroring.
How RAID 5 Provides Redundancy
RAID 5 provides redundancy by distributing parity information across all the drives in the array. Parity is calculated data that can be used to reconstruct missing or corrupted data in the event of a drive failure. Here’s how it works:
Data is broken into chunks called “stripes” that get written across the drives in the array sequentially. But in addition to the data stripes, parity stripes are also calculated and written. The parity is calculated by performing an XOR operation on the corresponding data stripes. So parity stripe 1 is calculated from data stripe 1 on each drive, parity stripe 2 is calculated from data stripe 2 on each drive, and so on.
If any single drive in the RAID 5 array fails, the system can use the parity information to reconstruct the missing data from that drive. For example, if drive 3 fails, the RAID controller can XOR data stripe 1 from drives 1, 2, 4, and 5 with parity stripe 1 to recreate the missing data. This provides fault tolerance and allows operations to continue with no data loss despite a drive failure (RAID 5 Explained).
RAID 5 requires a minimum of 3 drives to provide redundancy. The parity information is evenly distributed across all drives, so no single drive includes all the parity. This helps distribute the write load for parity calculations across the entire array.
How RAID 6 Provides Redundancy
RAID 6 provides redundancy through a dual distributed parity system. This means RAID 6 calculates and stores parity information across multiple drives, providing protection against up to two disk failures.
Specifically, RAID 6 stripes data and distributes parity information across all the drives in the array. The parity information is calculated and written across different drives, providing redundancy. If one drive fails, the remaining parity blocks can be used to reconstruct the lost data. If two drives fail, the dual parity blocks still enable recovery of the data (1).
This dual distributed parity is a key advantage of RAID 6 over other RAID levels. RAID 5 offers single distributed parity, meaning it can only tolerate a single drive failure before data loss occurs. The dual parity of RAID 6 provides much stronger protection and redundancy.
This makes RAID 6 ideal for mission critical applications or large arrays where the risk of multiple drive failures is higher. The redundancy of RAID 6 gives peace of mind that data is safe even if multiple drives fail.
Benefits of RAID Redundancy
One of the main benefits of RAID redundancy is increased reliability and fault tolerance. By duplicating data across multiple disks, RAID can prevent data loss if one drive fails. For example, in a RAID 1 configuration, data is mirrored between two disks. If one disk fails, the data is still accessible from the other disk. This provides protection against hardware failures and improves the overall reliability of the storage system.
RAID redundancy also helps prevent downtime and data loss in the event of a drive failure. With a redundant RAID configuration, a failed drive can simply be replaced or rebuilt without any data being lost. This fault tolerance ensures continuous availability and avoids disruptions to operations.
In addition, some RAID levels like RAID 0, RAID 5, and RAID 10 provide improved read and write performance by distributing data across multiple disks that can operate in parallel. This striping of data across drives increases overall throughput and access times. According to SalvageData, RAID improves performance two to eight times versus a single disk.
In summary, redundancy in RAID offers crucial protection, availability, and performance improvements for storage systems by duplicating data across drives.
Drawbacks of RAID Redundancy
While RAID redundancy provides significant benefits for data protection, it also comes with some potential drawbacks to consider:
Increased Cost – Implementing RAID requires additional drives, which increases the overall storage costs. The more redundancy built in, the more drives are required, driving up expenses. RAID controllers and enterprise-grade drives also add to the costs (https://www.stellarinfo.co.in/blog/advantages-and-disadvantages-popular-raid-systems/).
Added Complexity – Configuring and managing a RAID array adds complexity versus using single, standalone drives. Specialized RAID controllers are often required, and monitoring tools to track the status of rebuilding and disk failures may be needed. This can make RAID more complex for IT teams to deploy and manage.
Longer Rebuild Times – When a drive fails in a RAID 5, RAID 6 or other redundant array, the rebuild process to restore redundancy can take hours or days. The larger the drives, the longer rebuilds take, exposing the array to risk of a second drive failure during rebuild.
Wasted Storage Capacity – In an array like RAID 1 or RAID 5, part of the total capacity has to be reserved for redundancy/parity data. This means there is less usable capacity versus the raw capacity of all disks added together (https://ulink-da.com/pros-and-cons-of-redundant-array-of-independent-disks-raid/).
When To Use RAID Redundancy
RAID redundancy is most beneficial for high availability applications where downtime is unacceptable. Mission critical data and large storage systems also benefit greatly from the added protection of RAID. According to SalvageData, RAID redundancy helps prevent data loss and corruption by storing multiple copies of data across different disks. If one disk fails, the data can still be accessed from the other disks.
RAID redundancy is commonly used for databases, enterprise resource planning systems, email servers, and other business applications where downtime or data loss would be catastrophic. The redundancy provides an extra layer of protection so these systems can continue operating even if a disk fails. Large storage arrays often leverage RAID 6 which provides double parity data protection against up to two disk failures. For mission critical data, the added cost of RAID redundancy is well worth it for the reliability and availability it provides.
Conclusion
In summary, RAID provides different levels of data redundancy through disk mirroring or striping with parity. The key benefits of RAID redundancy are increased data protection against disk failures and improved read/write performance. The most common RAID levels that provide redundancy are RAID 1, RAID 5, and RAID 6.
RAID 1 duplicates data across multiple disks through disk mirroring. This allows for continuous availability and protection if one disk fails. RAID 5 stripes data and parity information across disks, allowing for recovery if one disk fails. RAID 6 is similar but provides protection if up to two disks fail.
While RAID redundancy comes with overhead costs, the benefits often outweigh the drawbacks for mission critical systems or high availability requirements. The redundancy of RAID ensures valuable data is not lost due to disk failures. By understanding the different RAID levels, you can select the right redundancy for your storage needs.