Both block and object storage are types of data storage used in computing, but which one offers better performance? The short answer is that block storage is generally faster for workloads that require low latency and frequent updates, while object storage scales better for large amounts of unstructured data.
What is Block Storage?
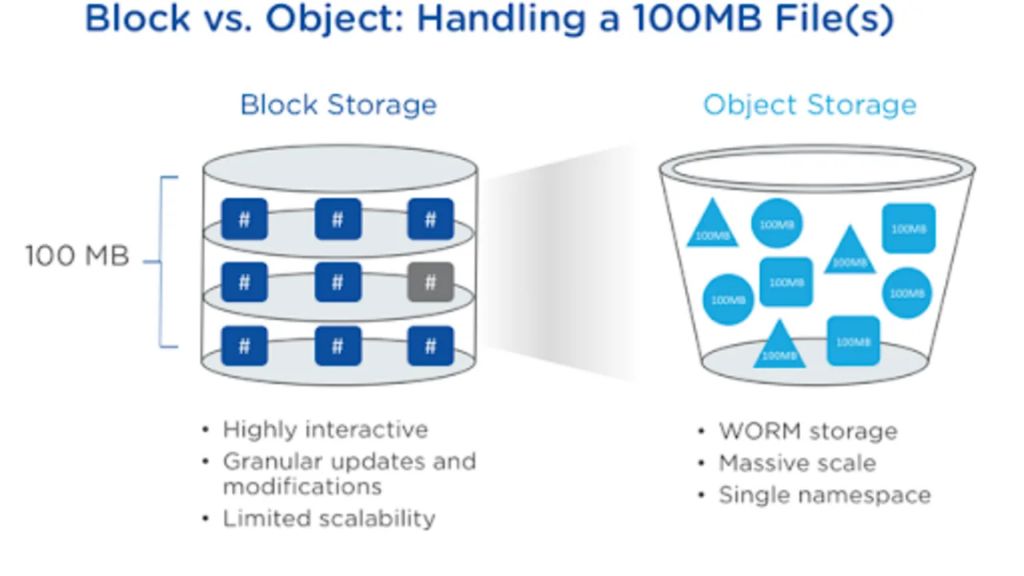
Block storage divides data into blocks within sectors and tracks on hard disk drives (HDDs) or solid-state drives (SSDs). Each block has a unique address called a logical block addressing (LBA). Block storage is accessed through protocols like Fibre Channel, iSCSI, and FCoE.
Some key characteristics of block storage:
- Data is accessed at the block level
- Low latency and high IOPS performance
- Supports random writes and rewrites
- Used for databases, transactional workloads
- Managed through a filesystem
- Limited scalability (100s of TBs)
On a physical server, block storage is connected through SAN protocols like Fibre Channel or iSCSI. In the cloud, block storage volumes can be mounted like virtual hard disks. AWS EBS volumes and Azure managed disks are examples of cloud block storage.
What is Object Storage?
Object storage manages data as objects in a flat namespace. Objects consist of the data itself, metadata, and an ID or key for retrieval. Objects are accessed through APIs like REST and SOAP.
Some key characteristics of object storage:
- Data is accessed through an API
- Scales to exabytes of data
- Eventually consistent
- Used for backups, archives, IoT data
- Self-describing through metadata
- Highly durable and available
Object storage is designed for web-scale applications that need massive amounts of unstructured data storage. Public cloud providers like AWS S3, Azure Blob Storage, and Google Cloud Storage offer object storage.
Block Storage vs. Object Storage
Here’s a comparison between block and object storage:
| Property | Block Storage | Object Storage |
|---|---|---|
| Access method | Block protocols (SCSI, iSCSI, FCoE) | HTTP APIs (REST, SOAP) |
| Performance | High IOPS, low latency | High throughput |
| Use cases | Transactional workloads (databases, VMs) | Backups, archives, content repositories |
| Scalability | 100s TBs | Exabytes |
| Availability | Snapshots for recovery | Replication across zones/regions |
As this comparison shows, block storage excels at low-latency workloads that demand high IOPS, like databases and virtual machines. Object storage can handle orders of magnitude more unstructured data and content, easily scaling into the exabytes.
Block Storage Use Cases
Here are some common use cases where block storage provides the best performance:
- Databases – Block storage delivers the low-latency and high IOPS needed for demanding database workloads like MongoDB, MySQL, and Oracle.
- Transactional applications – Applications like e-commerce, banking, and ERP rely on fast block storage to provide rapid responses to user requests and transactions.
- Virtual machine disks – VMs use block storage virtual disks to run their operating systems, applications, and data.
- AI and ML – Block storage offers the speed needed for machine learning training and inferencing data sets.
- Real-time analytics – Block storage enables fast analysis and queries against rapidly incoming streams of log and sensor data.
Any application that needs consistently fast writes and responses favors block storage. The low latency and high IOPS provide predictable performance crucial for these workloads.
Object Storage Use Cases
Here are some common use cases where object storage scales the best:
- Backup and archives – Object storage can retain massive backup data sets while providing built-in data integrity checks.
- Content repositories – Digital media catalogs with billions of photos, videos, and files can be stored and streamed from object storage.
- Big data analytics – Object storage efficiently handles enormous data sets for batch analytics like Spark and Hadoop.
- Software development – Dev teams can store code repositories and build artifacts in object storage.
- Static web content – Object storage can directly host static web content and CDN origin storage.
Any large application that needs scalable and durable storage favors object storage. The scale-out architecture allows practically unlimited capacity.
Block Storage Performance
Block storage delivers excellent performance by connecting servers directly to their storage volumes. Here are some typical performance numbers for block storage:
- Latency: <10 ms read/write latency
- IOPS: Up to 400,000 random read/write IOPS per volume
- Thoughput: Up to 10 Gbps throughput per volume
Performance scales with the number of volumes added, so clustered applications gain predictable speed improvements from adding block storage capacity.
Low latency and high IOPS make block storage ideal for demanding transactional workloads. For specific applications, databases can see 50-100x faster queries and VM storage achieves 200x faster boot times with block storage.
Object Storage Performance
Object storage uses a scale-out architecture to deliver high aggregate throughput, but lower per-object performance. Here are some typical object storage performance metrics:
- First-byte latency: 50-100 ms typical
- Throughput: Multiple GB/s per storage node
- IOPS: Low per-object, but scales with nodes added
Although a single object fetch sees higher latency, object storage achieves order-of-magnitude better throughput and scale compared to block storage. Parallel access to objects increases total throughput.
For large-scale workloads like backups and content streaming, object storage provides ample performance. Lower per-object performance is acceptable trade-off for massive scalability.
Block Storage Scalability
Block storage scales vertically by adding capacity to individual servers and storage systems. But there are scalability limits to a single storage array. Realistically, a high-end block storage system can scale to 100s of terabytes per cluster.
To go beyond those limits requires partitioning data across multiple block storage systems. This adds complexity, since now capacity needs to be managed across those disparate systems.
Block storage excels at delivering high performance for a single workload from one storage platform. But it was not designed to horizontally scale capacity across multiple storage systems for exabyte-level storage.
Object Storage Scalability
Object storage was designed from the ground up to scale horizontally across servers and locations. Additional object storage nodes increase capacity and throughput in a linear fashion.
A typical object storage node may provide 40 TB of capacity and 1 GB/s throughput. Clustering 100 nodes would provide 4 PB of capacity and 100 GB/s throughput. Additional nodes scale out the system linearly.
Object storage can readily scale to exabytes of capacity across on-premises or cloud data centers. A single global namespace allows apps to access objects across regions.
For massive storage needs, object storage can keep growing as capacity demands increase. This horizontal scalability enables practically unlimited storage for data that needs long-term retention.
Block Storage Availability
Block storage systems ensure high availability through:
- RAID protection – Striping replicas across drives protects against disk failures.
- Redundant systems – Clustered storage arrays avoid single points of failure.
- Snapshots – Point-in-time snapshots recover from accidental changes.
- Replicas – Synchronous replication copies data across mirrored systems.
Mission-critical applications rely on block storage’s robust availability capabilities. Built-in redundancy keeps workloads running through hardware failures and administrative mistakes.
Object Storage Availability
Object storage provides availability through:
- Erasure coding – Data is encoded across drives and nodes without replication.
- Geographic distribution – Objects are replicated across availability zones and regions.
- Versioning – Objects are versioned to recover from accidental overwrites.
Object storage is designed to provide 99.999999999% (11 nines) durability of objects. Data remains resilient even when entire data centers go offline.
Spreading object replicas across geographic regions allows object storage to withstand region-level disasters. Apps can continuously access objects globally.
Block Storage in the Cloud
Cloud block storage provides iSCSI-based volumes that virtual machines can mount and access like traditional physical storage. Cloud block storage is implemented through services like:
- Amazon Elastic Block Store (EBS)
- Azure managed disks
- Google persistent disks (PDs)
Cloud block storage removes the need to provision local storage hardware. Volumes can be created quickly to meet application performance and capacity needs.
Cloud block storage also enables advanced features like:
- Dynamic volume scaling
- IOPS provisioning
- Byte-level snapshots
- Replication across zones
- Encryption
Migrating workloads to the cloud can take advantage of cloud block storage’s scalability, availability, and advanced data services.
Object Storage in the Cloud
Cloud object storage provides durable and highly-scalable storage through services like:
- Amazon Simple Storage Service (S3)
- Azure Blob Storage
- Google Cloud Storage
Object storage removes the need to build and manage storage infrastructure. Cloud services handle capacity scaling and hardware failures behind the scenes.
Cloud object storage enables features like:
- Tiered storage classes
- Object versioning
- Cross-region replication
- Encryption
- Object locking
- Lifecycle management
For a virtually unlimited capacity pool, cloud object storage can consolidate massive amounts of data into centralized repositories accessed across regions.
When to Use Block Storage
Here are guidelines on when to choose block storage for a workload:
- Apps need low latency, high IOPS performance
- Data sets are structured and need frequent updates
- Requirements are within block storage scalability limits
- Strong consistency semantics are required
- Workloads are localized to a single region
Block storage fits transactional applications that need consistently fast performance for a single node or cluster. It’s a great choice for localized workloads up to hundreds of terabytes.
When to Use Object Storage
Here are guidelines on when object storage fits best:
- Need limitless scalability for growing storage
- Accessing semi-structured or unstructured data
- Serving large amounts of content
- Building data lakes and archives
- Global collaboration is required
Object storage suits scale-out workloads managing huge amounts of unstructured data across regions. It can consolidate massive archives and content repositories.
Conclusion
Block and object storage excel in different domains. Block storage provides high performance for transactional and VM workloads. Object storage scales seamlessly to multi-petabyte repositories.
For low-latency databases, block storage is the clear choice. For massive content distribution, object storage easily serves exabyte scale needs.
Many real-world solutions combine block and object storage. A layered approach places frequently accessed “hot” data on block storage while archiving “cold” data to object storage. This balances performance and scale.
As global data sets continue exponential growth, both block and object storage will play crucial infrastructure roles. Block provides localized speed while object enables unlimited capacity. The complementary strengths of each make them foundational building blocks for the future of enterprise storage.