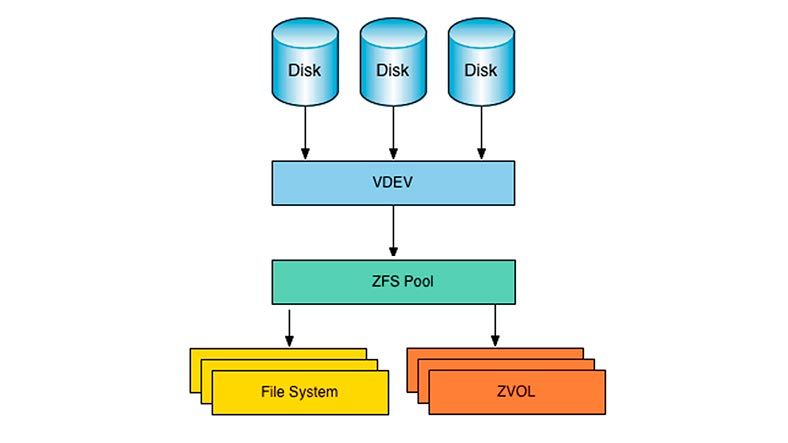
ZFS (Zeta File System) was originally developed by Sun Microsystems for the Solaris operating system in 2005. It is a high performance filesystem that provides pooled storage, snapshots, data integrity verification, automatic repair, and more. In 2013, the ZFS on Linux (ZoL) project brought ZFS to Linux systems, making the advanced features of ZFS available on the popular open source operating system.
ZFS on Linux allows administrators to take advantage of ZFS benefits like data integrity, performance, scalability, and powerful tools like snapshots/clones on their Linux machines. With the stability and ubiquity of Linux combined with the resilience and management capabilities of ZFS, it offers a compelling option for many use cases from personal storage to enterprise servers.
This article will examine the key advantages of using ZFS on Linux platforms and why it may be preferable over traditional Linux filesystems for certain needs. The advanced feature set and reliability of ZFS can provide major benefits for Linux users willing to learn this new-to-Linux filesystem option.
Data Integrity
One of the key features of ZFS is its focus on data integrity. ZFS uses checksums to verify data integrity and prevent silent data corruption. As data is written, a 256-bit checksum is calculated and stored. When data is read, the checksum is recalculated and verified against the stored checksum (1). If a mismatch is detected, ZFS will automatically heal the corrupted data from a valid copy such as a snapshot or mirrored copy (2). This protects against bit rot, phantom reads, misdirected reads/writes, and other causes of data corruption.
ZFS also leverages snapshots to provide point-in-time copies of filesystems for backup and restoration purposes. Snapshots are extremely space efficient, since only the changed data blocks need to be saved. This allows frequent snapshots to be taken, providing multiple restore points. Snapshots can be rolled back instantly to revert a filesystem to an earlier state. Overall, ZFS’s integrity features and snapshot capabilities significantly enhance data protection compared to traditional filesystems (3).
(1) https://www.usenix.org/events/fast10/tech/full_papers/zhang.pdf
(2) https://klarasystems.com/articles/openzfs-data-security-vs-integrity/
(3) https://www.open-e.com/blog/data-integrity-raidz/
Performance
One of the key performance advantages of ZFS on Linux is its adaptive caching algorithms. As explained in this Reddit thread, ZFS dynamically adapts to workload patterns, retaining frequently accessed data in RAM while evicting cold data. This allows frequently used files to be served from memory at RAM speeds rather than relying on relatively slow mechanical hard disks. ZFS also prioritizes caching metadata which contains information about files and directories. Caching metadata allows quick traversal and lookups in large filesystems with billions of files.
In addition, ZFS is designed for parallelization and can take advantage of multiple cores and threads. As described in the Reddit thread, ZFS uses lock-free data structures and per-CPU threads to scale nearly linearly across many cores. This allows ZFS to fully utilize the power of modern multi-core systems for increased performance. ZFS also stripes data across all disks by default allowing large sequential workloads to saturate disk bandwidth by reading/writing to disks in parallel.
Scalability
One of the most notable features of ZFS is its virtually unlimited scalability. With 128-bit architecture, ZFS can theoretically store up to 256 quadrillion zettabytes of data (Oracle ZFS Docs). For comparison, 64-bit file systems like Btrfs max out at 16 exbibytes. This enormous capacity means that for all practical purposes, ZFS does not have any limits on storage or file sizes (Wikipedia).
ZFS storage pools are also designed to be easily expandable over time. Additional disk drives can be added to grow the capacity of a pool. There is no need to preallocate storage either. The flexible architecture of ZFS allows pools to scale organically as more space is needed (Stack Exchange). This makes ZFS storage highly adaptable and future-proof for systems large and small.
Data Deduplication
One of the key features of ZFS is its ability to deduplicate data to save storage space. Data deduplication works by analyzing blocks of data and only storing identical blocks once. If a file or snapshot contains redundant blocks, those blocks are replaced with a pointer to the single stored copy. This can significantly reduce the amount of storage space required since duplicate data is not stored multiple times.
The amount of storage savings from deduplication varies greatly based on the dataset and workload. In general, datasets with many redundant blocks like virtual machine images, backups, and user home directories tend to see higher deduplication ratios. Some users report 2-5x reductions in storage from dedup on eligible datasets [1]. However, databases and other frequently written or unique data will see little to no space savings. The deduplication ratio can be checked with zfs list -o space,dedup on datasets.
Deduplication does come with additional RAM and CPU overhead to fingerprint and compare blocks. Each unique block requires a small amount of RAM overhead. As such, adequate free memory is required for deduplication to be effective. The general recommendation is 5-10 GB RAM per TB of storage to be deduplicated [2]. The processing requirements for deduplication can also impact performance, especially for large initial scans. However, modern processors are generally able to handle the load.
Compression
ZFS offers both inline and post-process compression. Inline compression means data is compressed as it is written to disk, while post-process compression compresses data after it is written. Inline compression provides better performance, while post-process can achieve better compression ratios. However, the savings from compression depends heavily on the compressibility of your data. Highly compressible data like text files will see large reductions from compression. Already compressed formats like JPEGs will see little to no space savings from further compression.
According to one real world test, the LZ4 compression algorithm provided a good balance of compression ratio and performance (https://www.reddit.com/r/zfs/comments/svnycx/a_simple_real_world_zfs_compression_speed_an/). LZ4 achieved compression ratios of 2.03x on media files and 2.73x on VMs, while maintaining high write speeds. Other tests have shown compression ratios up to 4-5x on highly compressible data (https://www.nixcraft.com/t/how-to-show-compression-ratio-on-zfs/3665). The key is matching the compression algorithm to your specific data profile for the best results.
Snapshots and Clones
One of the standout features of ZFS is its lightweight snapshots. Unlike other filesystems, ZFS snapshots have little to no performance impact, even if you have thousands of them. This is because snapshots in ZFS use copy-on-write technology and are space efficient (Klara Inc). When a snapshot is taken, it simply references the existing data blocks – new writes are redirected to different blocks while the snapshot preserves the old data. This means snapshots take up little space and have minimal overhead (Ahrens).
In addition to snapshots, ZFS also supports space-efficient clones. A clone is created from a snapshot and shares common data blocks with the snapshot. This means clones only use additional space for new writes, saving substantial space for multiple copies (Reddit). Both snapshots and clones provide powerful data management capabilities in ZFS.
Administration
ZFS provides powerful command line and graphical user interface tools for managing ZFS configurations and performing tasks like creating pools and file systems, setting quotas, taking snapshots, and more. For example, the zpool, zfs, and zdb commands provide low-level control over ZFS at the command line. Tools like Solaris System Administration GUI (SAGC) and Oracle Enterprise Manager Ops Center offer easy-to-use graphical interfaces for common ZFS administration tasks.
ZFS also supports role-based access control (RBAC), allowing administrators to restrict certain users or groups to specific subsets of pools and file systems. For example, one group could be limited to managing only file systems for particular projects or departments. This enhances security and isolation between different groups in an organization. The zfs allow and zfs unallow commands provide fine-grained control over which users can perform which ZFS operations.
Drawbacks
Two common drawbacks cited with using ZFS on Linux are its RAM requirements and inability to do in-place upgrades. ZFS is known to use large amounts of RAM compared to traditional filesystems, especially if data deduplication is enabled. This is because ZFS is designed to cache data in RAM for performance. One source notes “The biggest downside is that it uses gobs of memory in the best case, and gobs upon gobs of memory if you turn on deduplication.”[1]
Another drawback is that ZFS does not support in-place upgrades of the pool, unlike some other filesystems. When upgrading ZFS, the pool must be exported and re-imported after upgrading the system, rather than being upgraded live. According to one analysis, “ZFS does not support online pool upgrade. The pool must be unmounted and upgraded with the new binaries.”[2] This complicates the upgrade process and means some downtime when migrating to new ZFS versions.
Conclusion
ZFS on Linux offers numerous benefits for certain use cases that make it an excellent choice of filesystem in the right scenarios. The key advantages of ZFS include its robust data integrity checking, great performance especially with large files, highly scalable architecture, powerful data deduplication and compression, writable snapshots and clones, and advanced administration features. ZFS is well suited for use cases that demand maximum data integrity like storage servers, NAS devices, backup storage, databases, and other mission-critical data. The self-healing data integrity, snapshots, and clones provide excellent protection against data loss and downtime. The performance, scalability, deduplication, and compression excel at maximizing storage efficiency for large datasets. The advanced administration also helps manage large storage deployments. For Linux users with these demanding data storage needs, ZFS is highly recommended and delivers significant advantages over traditional filesystems.