RAID (Redundant Array of Independent Disks) is a technique that combines multiple disk drives into a logical unit to improve performance and/or reliability. One key component of many RAID implementations is parity. Parity allows data to be recovered in the event of a disk failure by calculating missing data from the remaining disks. There are several different parity schemes used in various RAID levels, each with their own advantages and disadvantages. In this article, we will examine the most common parity implementations found in RAID.
What is parity and how does it provide redundancy?
Parity is a calculated value used to reconstruct data in the event of a failure. Parity data is calculated by performing an exclusive OR (XOR) operation on data blocks. The result of the XOR operation is stored as the parity block.
For example, consider two data blocks:
Data Block 1: 10101010
Data Block 2: 11001100
If we perform an XOR operation on these two blocks, the result is:
Parity Block: 01100110
Now imagine if Data Block 2 were to fail. We still have Data Block 1 and the Parity Block. We can reconstruct Data Block 2 by performing another XOR operation between Data Block 1 and the Parity Block:
Data Block 1: 10101010
Parity Block: 01100110
XOR Result: 11001100 (Reconstructed Data Block 2)
This demonstrates how parity allows data to be reconstructed in the event of a single disk failure. The XOR operation is performed across multiple data blocks and disks in more advanced RAID implementations.
RAID Level 0
RAID 0 is not true RAID since it does not provide any redundancy. RAID 0 simply “stripes” data evenly across multiple disks with no parity. This improves performance by allowing reads and writes to be distributed across multiple disks. However, it does not provide any fault tolerance. If any disk fails in a RAID 0 array, all data will be lost.
Advantages of RAID 0
- High disk performance – data is striped across multiple disks allowing reads/writes to be done in parallel
- Low disk overhead – no parity calculation reduces processor usage
Disadvantages of RAID 0
- No fault tolerance – if one disk fails, all data is lost
- Low storage efficiency – storage capacity is limited to the smallest disk in the array
RAID 0 is useful in situations where performance is critical and data redundancy is not required. Examples include cache servers, scratch disks, and video editing workstations. The lack of redundancy means RAID 0 should never be used for mission critical data storage.
RAID 1
RAID 1 provides complete data redundancy through disk mirroring. Two or more identical copies of data are stored on separate disks. If one disk fails, the data can still be accessed from the mirror disk(s). RAID 1 ensures high availability and fault tolerance.
How does mirroring work in RAID 1?
All data is duplicated onto mirror disks in real-time. When a write request occurs, data is written to all disks simultaneously. Similarly, reads can be performed in parallel from multiple disks. This allows RAID 1 arrays to handle high read workloads. Writes are slower however, since every write operation must be performed multiple times to different disks.
Advantages of RAID 1
- Complete data redundancy – data remains available if a disk fails
- High read performance – reads can be distributed across multiple disks
- Simple to implement
Disadvantages of RAID 1
- High disk overhead – requires at least double the storage capacity
- Slower writes – every write must go to every mirror disk
- Low storage efficiency – capacity is limited to the smallest mirrored disk
RAID 1 is suited for situations requiring high availability and fault tolerance like critical databases or virtualization storage. The reduced write performance means it may not be ideal for high traffic transactional workloads.
RAID 5
RAID 5 uses distributed parity to provide redundancy while also overcoming some of the capacity limits of mirroring. Data and parity is striped across all disks. If a disk fails, the missing data can be recalculated from the remaining data and parity blocks.
How does distributed parity work in RAID 5?
Unlike RAID 1 where all data is duplicated onto multiple disks, RAID 5 distributes parity across all the disks. Here is a simplified example:
– Disk 1 contains data blocks A1 and B1
– Disk 2 contains data blocks A2, B2, and Parity P
– Disk 3 contains data blocks A3 and B3
The parity block P is calculated by XORing corresponding data blocks from the other disks (A1 XOR A2 XOR A3 = P).
If Disk 2 fails, we can reconstruct its data by:
– A2 = A1 XOR A3 XOR P
– B2 = B1 XOR B3 XOR P
Advantages of RAID 5
- Good read performance – reads are distributed across multiple disks
- Only one parity disk required – low overhead compared to mirroring
- High storage efficiency – total capacity is (N-1) disks worth of space where N disks in total
Disadvantages of RAID 5
- Slow writes – parity must be updated on every write
- Poor performance during rebuilds – entire array is vulnerable during disk rebuilds
- Disk failure results in reduced array capacity
RAID 5 provides a good balance between redundancy, capacity, and performance for general use cases like file servers and databases. The parity overhead makes it less suitable for high write workloads.
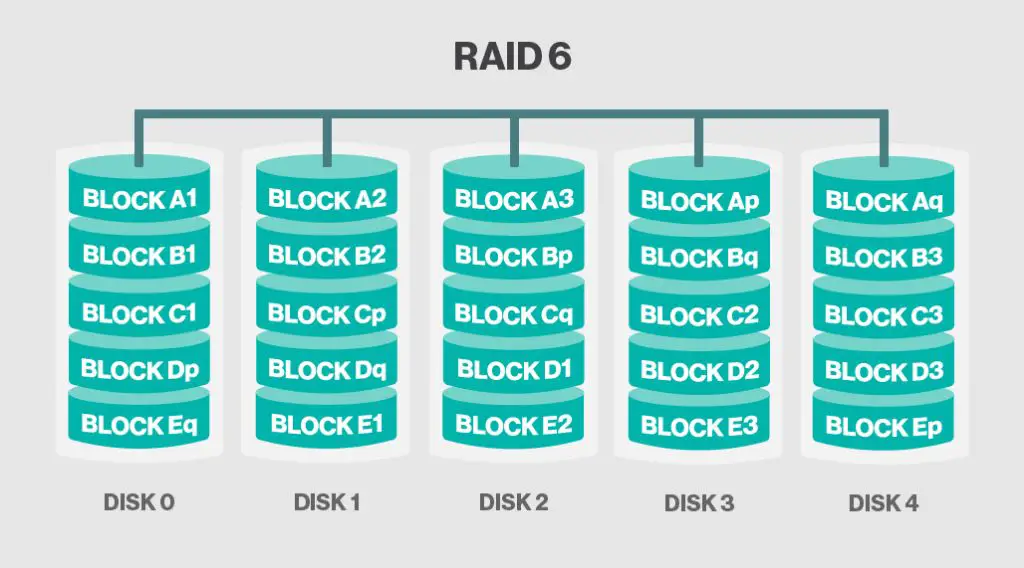
RAID 6
RAID 6 provides additional fault tolerance over RAID 5 by using double distributed parity. Data is striped across disks similar to RAID 5, but two separate parity blocks P and Q are calculated and distributed across all disks. This allows the array to withstand the failure of two different drives.
How does double parity in RAID 6 provide additional redundancy?
With two parity blocks, RAID 6 can recover data after losing any two disks in the array. Here is a simple example:
– Disk 1 contains data blocks A1, B1 and parity Q
– Disk 2 contains data blocks A2, B2 and parity P
– Disk 3 contains data blocks A3, B3
If both Disk 1 and Disk 2 fail, we can reconstruct the data as follows:
– A1 = A2 XOR A3 XOR P XOR Q
– B1 = B2 XOR B3 XOR P XOR Q
The second parity block provides additional fault tolerance and allows RAID 6 to recover from two disk failures. This prevents data loss when reconstructing one failed drive and a second drive fails before the rebuild completes.
Advantages of RAID 6
- Tolerates up to two disk failures
- Avoid data loss during rebuilds if second disk fails
- High storage efficiency – total capacity is (N-2) disks worth of space where N disks in total
Disadvantages of RAID 6
- Higher parity overhead than RAID 5 – requires two parity disks
- Slower write performance than RAID 5 due to additional parity calculations
- Longer rebuilds than RAID 5
RAID 6 is well suited for mission critical storage systems that require high fault tolerance like financial databases or virtualization storage. The performance tradeoffs mean it is less ideal for systems with high transactional workloads.
Choosing the right parity RAID level
Deciding which parity RAID level to implement depends on your specific availability, capacity, performance, and budget requirements. Here are some general guidelines:
- RAID 0 – High performance but no redundancy. Use for cache servers and other non-critical workloads.
- RAID 1 – Simple mirroring for maximum availability. Use for critical systems like databases.
- RAID 5 – Good balance of capacity and performance. Use for general file and application servers.
- RAID 6 – Maximum redundancy and fault tolerance for critical data. Use for mission critical systems.
You should also consider the workload patterns in terms of reads versus writes. Parity RAID levels involve write penalties that can significantly affect performance for write heavy workloads. Benchmarking your systems with different RAID levels can help determine the optimal implementation.
Hybrid RAID implementations
Many RAID implementations combine parity and mirroring to get optimal performance or create nested RAID levels. Here are some examples of hybrid RAID:
RAID 1+0 (RAID 10)
RAID 10 combines mirroring and striping for both performance and redundancy:
- RAID 1 mirroring is implemented first to duplicate all data
- Then RAID 0 striping is applied across the mirrors to distribute IO
This provides fast read/writes and fault tolerance from disk failures. However, storage efficiency is low due to mirroring overhead.
RAID 5+0 (RAID 50)
RAID 50 combines the distributed parity of RAID 5 with RAID 0 striping:
- RAID 5 parity is calculated across a set of disks
- Then RAID 0 striping is applied across the RAID 5 sets
This improves performance by distributing Reads/writes while also providing fault tolerance through parity. Storage efficiency is also higher than RAID 10.
RAID 60
Similar to RAID 50 but uses RAID 6 double parity instead of RAID 5 for higher fault tolerance:
- RAID 6 parity is calculated across disks
- Then RAID 0 striping is applied across the RAID 6 sets
RAID 60 combines the high availability of RAID 6 with the parallel throughput of RAID 0. It requires more disks than RAID 50 however.
Non-standard RAID implementations
In addition to standard RAID levels, some vendors have created proprietary RAID schemes optimized for specific use cases:
NetApp RAID-DP
NetApp’s RAID Double Parity is similar to RAID 6 but uses variable stripe block sizes optimized for their WAFL file system. This customizes parity calculations for different workload patterns.
EMC EVENODD
EVENODD from EMC provides double parity protection but requires less overhead than RAID 6. However it involve more complex calculations and is proprietary to EMC.
Linux MD-RAID
The Linux kernel supports software RAID through MD-RAID. This allows creation of many standard and non-standard RAID levels. Unique options include RAID 4 style parity and three disk parity RAID levels.
While proprietary RAID implementations can provide benefits, they also have the downside of vendor lock-in and lack of portability. Standards-based RAID levels are more broadly supported across devices and operating systems.
Hardware versus software RAID
RAID can be implemented in hardware or software:
Hardware RAID
Performed by a dedicated RAID controller. The controller handles all parity calculations and redundancy operations. Hardware RAID provides high performance but less flexibility.
Software RAID
RAID calculations are performed by the operating system and drivers. This allows implementation across inexpensive commodity disks. Software RAID provides more flexibility and customization but at the cost of some performance overhead.
Comparison between hardware versus software RAID
| Factor | Hardware RAID | Software RAID |
|---|---|---|
| Performance | Higher throughput | Slower performance |
| Flexibility | Limited options and customization | Very flexible with ability to customize |
| Complexity | Simple to manage | More complex to implement and manage |
| Cost | More expensive | Low cost using commodity disks |
In general, hardware RAID performs better but software RAID is more flexible. Certain workloads like large databases benefit more from hardware RAID while virtualization and cloud storage can leverage software RAID.
Conclusion
There are many parity schemes and RAID options available, each with their own performance characteristics, fault tolerance guarantees, and capacity overhead. Key factors to consider when choosing a RAID implementation are:
- Application workload patterns – Reads vs Writes, sequential vs random, etc.
- Performance requirements – Throughput, IOPS, latency
- Availability needs – Tolerance for downtime and data loss
- Storage capacity requirements
- Ease of management and monitoring
RAID improves availability, throughput, and capacity compared to single disks. But RAID alone is not a backup solution. Maintaining multiple copies through backups is crucial for protecting against data loss from software bugs, human errors, malware, and physical disasters that can corrupt RAID arrays. Intelligently combining RAID with comprehensive backup provides highly available and resilient storage infrastructure.