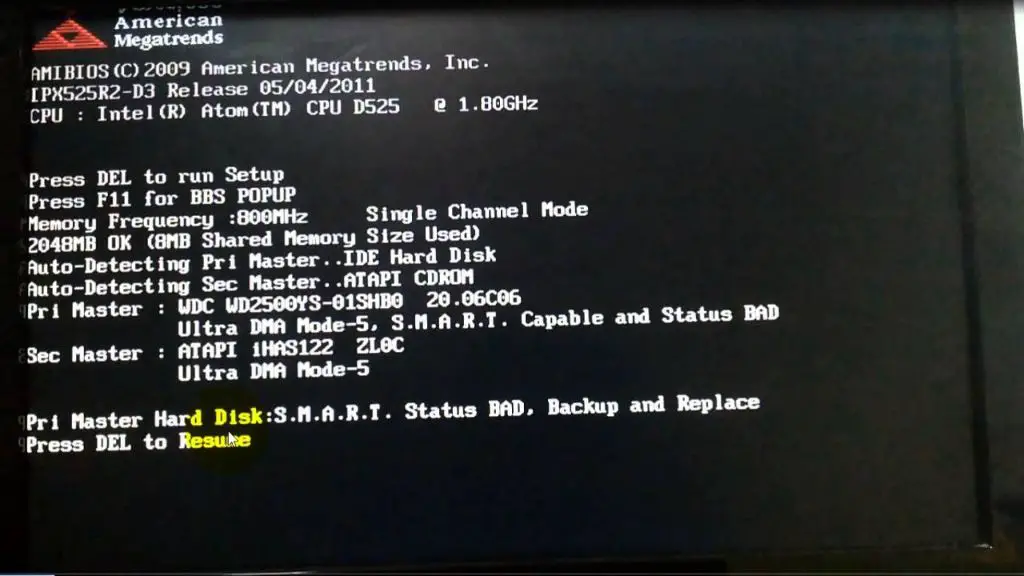
The S.M.A.R.T. status refers to the Self-Monitoring, Analysis and Reporting Technology status of a hard drive. S.M.A.R.T. is a monitoring system built into storage devices such as hard disk drives (HDDs) and solid-state drives (SSDs) that detects and reports on various indicators of drive health and reliability.
The SMART status monitors key attributes related to the drive’s operation, like the temperature, number of bad sectors, read/write errors, and other indicators that could potentially predict an impending drive failure. If problems are detected with any of these attributes, the drive’s SMART status will be reported as “failing.” Errors in the SMART status often indicate that the drive has failed or is likely to fail in the near future, necessitating backup and replacement.
What is a SMART Status?
SMART stands for Self-Monitoring, Analysis and Reporting Technology. It is a monitoring system built into computer hard disk drives (HDD) and solid-state drives (SSD) that detects and reports on various indicators of drive reliability. The goal of SMART is to warn users of impending drive failures while there is still time for the user to take preventative action.
SMART-capable drives use built-in sensors to monitor things like drive temperature, mechanical wearing, read/write errors, bad sectors, spin-up time, and numerous other internal metrics. The values from these sensors are then used to calculate the SMART status for the drive.
There are two types of SMART attributes: pre-failure and usage attributes. Pre-failure attributes directly indicate the state of the drive, while usage attributes indicate how much the drive has been used. By monitoring both types of attributes over time, SMART aims to provide advance warning of potential drive issues before failure occurs.
Most modern hard drives support SMART. You can check the SMART status in the BIOS at boot-up or within various drive utilities in Windows or Mac OS. A “good” SMART status indicates the drive is functioning normally, while a “bad” status means the drive is having issues and may fail soon.
Sources:
https://www.digitalcitizen.life/simple-questions-what-smart-what-does-it-do/
Backup and Replace
The SMART status error “Backup and Replace” is one of the common messages you may see. If your computer encounters the error, “S.M.A.R.T. Status BAD, Backup and Replace,” it means the hard drive is failing and needs to be replaced soon based on the SMART diagnostics. Such an error message shows that the hard drive has reached the end of its lifespan and could crash at any time, resulting in potential data loss [1].
The “Backup and Replace” error specifically means that the hard drive has started developing bad sectors. Bad sectors are parts of the hard drive that can no longer reliably store data due to physical damage or manufacturing defects. As the number of bad sectors increases, the hard drive has a higher risk of crashing and becoming completely unusable [2].
Therefore, when you see the “S.M.A.R.T. Status BAD, Backup and Replace” error, it means your hard drive has started developing bad sectors and is at high risk of failure. You should immediately backup your data and replace the drive to avoid potential data loss.
Causes
The main cause of the “SMART Status Bad Backup and Replace” error is a failing or faulty hard drive. Specifically, this error indicates that the hard drive has bad sectors or corrupted data that is triggering SMART (Self-Monitoring, Analysis and Reporting Technology) to detect the issue and display the warning message (Computer Hope). Bad sectors are sections of the hard drive that can no longer reliably store data due to physical damage or corruption. Over time, bad sectors spread, eventually leading to irrecoverable data loss and hard drive failure.
According to Wondershare, the “SMART Status Bad” error appears when SMART detects that the hard drive has used its reserved sectors set aside to reallocate data from bad sectors. Once the reserve sectors are depleted, the hard drive can no longer reallocate data, hence the “Backup and Replace” message. This indicates the hard drive problems have reached a critical point and complete failure is imminent (Wondershare).
Diagnosing the Issue
When you receive the “S.M.A.R.T Status BAD, Backup and Replace” error message, the first step is to diagnose the issue to determine the cause. There are a couple ways to do this:
Check the S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) attributes of the drive using disk utility software like HD Sentinel. S.M.A.R.T provides insight into the health of your hard drive. If the S.M.A.R.T status shows the drive is failing or damaged, that is likely the cause of the error message.
Run diagnostic tests on the drive like chkdsk in Windows or fsck in Linux. These will scan the drive and report any errors found. If bad sectors are detected, that’s a sign the physical drive is failing.
Use the disk manufacturer’s utility software to run drive tests. Most hard drive companies like Seagate and Western Digital provide software to test drive health. These programs will perform read/write tests and thoroughly examine the drive.
Checking S.M.A.R.T attributes and running drive tests will help determine if the backup and replace error is due to physical failure of the hard drive.
Resolving the Error
There are a few ways to try resolving the SMART status bad backup and replace error:
- Repair bad sectors – Tools like EaseUS Partition Master can scan your hard drive and repair any bad sectors that are causing the SMART error. This may resolve the issue without having to replace the drive.
- Replace the hard drive – If repairing bad sectors doesn’t fix the problem, the hard drive itself may be failing. Replacing the drive with a new one should resolve the SMART error for good. Be sure to back up any important data first.
- Update drivers – Outdated disk drivers can sometimes cause SMART errors. Update your hard drive drivers as well as your disk controller drivers.
- Disable SMART monitoring – You can disable SMART monitoring in the BIOS as a temporary workaround. However, this means you won’t get any advance warning of drive failure.
If the error persists even after trying these steps, the hard drive is likely failing and should be replaced. SMART errors indicate the drive has bad sectors that eventually lead to irreparable mechanical failure. Replacing a failing drive before complete failure occurs allows you to recover data off the old drive.
Preventative Measures
There are a few key preventative measures you can take to avoid the “SMART Status Bad Backup and Replace” error or minimize potential data loss:
Regular backups – Back up your hard drive data regularly, whether to an external drive, the cloud, or a network storage device. This ensures you have copies of your important files if your drive fails. Frequent backups let you restore data from a point closer in time to when the failure occurred, minimizing potential data loss.
Monitor SMART data – Use hard drive utilities that can read a drive’s SMART (Self-Monitoring, Analysis and Reporting Technology) data. This data provides insight into the drive’s health and can warn of problems before failure occurs. Watch for high bad sector counts or reallocated sector counts, as these indicate issues.
Replace aging drives – Hard drives have a limited lifespan, usually 3-5 years for desktop drives and less for heavily used enterprise drives. Replace older drives proactively before failure occurs. SSDs also degrade over time.
Maintain drive health – Avoid shock, impacts, and vibrations that can damage drives. Keep drives sufficiently cool and well-ventilated. Follow manufacturer guidelines on usage to maximize drive lifespan.
With preventative steps like these, you can catch drive issues early and avoid both data loss and “SMART Status Bad Backup and Replace” errors.
Data Recovery
If your hard drive is failing and you need to recover data, you have a few options:
You can try running data recovery software like Wondershare Recoverit to scan the drive and retrieve files. This works best if the drive is still partially readable. Recoverit can recover data from formatted, corrupted, or even deleted partitions.
Another option is to remove the drive and connect it to another computer as a secondary drive. This allows you to access the files directly or run data recovery software on the drive without interference from the original system. However, don’t continue using a failing drive in this way.
For advanced recovery, you may need to send the drive to a professional data recovery service. They have specialized tools to repair drives and extract data even from drives with advanced failures. This can be expensive but is sometimes the only way to retrieve critical files.
As a preventative measure, always keep backups of important data on a separate drive. This gives you a copy if your main drive fails. Cloud backup services like iDrive and Backblaze are affordable options.
Alternatives to Replacing the Drive
While the “Smart Status Bad Backup and Replace” error often indicates a failing hard drive that may need replacement, there are some alternatives that can potentially extend the life of the drive or avoid replacement altogether:
SSD Caching: One option is to add an SSD as a cache drive for the hard disk. The SSD cache stores frequently accessed data and improves overall system performance, reducing strain on the HDD. This can potentially prolong the life of the hard drive. However, it’s only a temporary solution if the HDD is failing (source).
Cloning to a New Drive: Cloning involves making an exact copy of the HDD to a new, healthy drive. This allows continued use of the data while avoiding reliance on the failing drive. However, the clone process can further degrade a failing drive. So cloning should be done as soon as errors appear (source).
These alternatives provide ways to temporarily extend the life of a failing HDD exhibiting “Smart Status Bad” errors. But replacement will still be required if the drive continues to degrade.
Conclusion
In summary, the “smart status bad backup and replace” error message indicates an issue with a hard drive that supports SMART (Self-Monitoring, Analysis and Reporting Technology). This error suggests the drive is failing and should be replaced to avoid potential data loss.
The most common causes are physical damage, logical/firmware corruption, or excessive wear from age. Diagnosing the root issue involves checking SMART attributes with disk utility software. While data recovery and cloning the drive are possible short-term solutions, replacement is recommended for long-term reliability.
To prevent this error in the future, handle drives gently, manage heat and vibration, update firmware when available, and follow a regular backup routine. SSDs are less prone to physical failure over time versus traditional HDDs. But all drives eventually wear out, so monitoring health and planning drive replacements in advance is key.
While frustrating to deal with, the “smart status bad” warning provides an important alert that drive problems are occurring. Heeding this message and taking prompt action can help avoid catastrophic failure and permanent data loss down the road.
