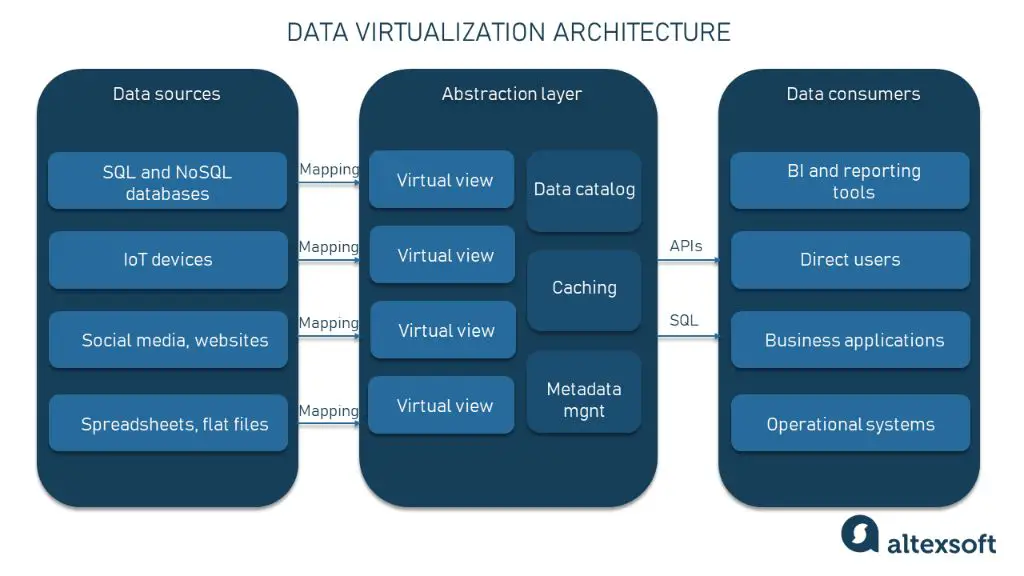
Data virtualization is a hot topic in the world of data management. In simple terms, data virtualization provides access to data from multiple systems through a single virtual layer. This simplifies data access by eliminating the need to know where the data is physically located or how it is stored.
Data virtualization acts as an abstraction layer that sits on top of an organization’s various data sources. It uses metadata to map the relationships between data sources and provide a unified view of the data. Users query and access data without being aware of the technical complexities of the underlying systems.
Some key benefits of data virtualization include:
– Simplified data access – Users access data through semantic names rather than needing to know technical details.
– Increased agility – New data sources can be added without disrupting existing structures.
– Reduced costs – Less data replication and movement since data does not need to be physically integrated.
– Single source of truth – Business users can access authoritative, consistent data.
– Speed and flexibility – Users can get real-time access to data across systems. Queries can join data across sources.
What problems does data virtualization solve?
Data virtualization helps organizations solve several common data management challenges:
– Data silos – Most organizations have data spread across multiple systems and databases. Each system acts as an island with its own access requirements. Data virtualization provides a unified view regardless of where data lives.
– Data duplication – Without data virtualization, organizations often create multiple copies of data in an attempt to simplify access. This redundancy is expensive and creates inconsistencies. Virtualization provides a single logical view without duplication.
– Inflexible pipelines – Typical ETL (extract, transform, load) processes require moving data to target databases. This makes it rigid and hard to add new data sources. Virtualization queries data in place avoiding lengthy data movements.
– Slow access – Integrating data from multiple systems often means periodic data warehouse refreshes. If users need current data, they are stuck waiting for updates. Virtualization queries sources in real-time.
– Scattered business logic – Without virtualization, organizations embed business logic across multiple applications. Centralizing logic in the virtual layer makes it reusable and maintainable.
Core capabilities of data virtualization
Data virtualization provides a number of core capabilities that enable simplified information access:
– Abstraction – The virtualization engine abstracts physical data structures from logical users needs. Users access data via business concepts.
– Federation – Virtualization can join data across multiple sources providing a single result set. Users don’t need to query each source separately.
– Transformation – Data from sources can be transformed to match user needs. For example, handling different code sets.
– Caching – Virtualization engines can cache commonly requested data sets to optimize performance.
– Catalog – The catalog maps business concepts to underlying sources providing flexibility to change physical systems.
– Service enablement – Virtualization can expose data services for reuse across applications and integration projects.
Key components of a data virtualization solution
A data virtualization solution typically consists of the following components:
– Metadata catalog – Stores mappings, interfaces, data types, and other metadata. Acts as the heart of the system.
– Query engine – Enables building queries that join and transform data across sources dynamically. Optimizes query execution.
– Abstraction layer – Provides logical mapping layer that insulates users from source details.
– Connectors – Software components to interface with various data sources like relational databases, APIs, files, etc.
– Data services – Services that encapsulate common query and data access patterns for reuse.
– Management console – Interface for managing the solution including monitoring usage, performance, creating mappings, etc.
How does data virtualization work?
At a high level data virtualization works as follows:
1. Query comes into the data virtualization engine from an application or user.
2. The engine analyzes the query and checks the metadata catalog to map logical objects to physical sources.
3. Needed connectors are invoked to retrieve data from the underlying sources.
4. Data is staged in a virtual workspace and transformed if needed.
5. The virtualized data is sent back to the requester.
This process is handled automatically by the virtualization engine. Users only see a simplified logical view of the data.
Key steps when building a data virtualization solution
– Inventory data sources – Discover all sources to be integrated. Document attributes, structures, security protocols etc.
– Model data objects – Define logical business objects or entities needed by users. Map attributes to sources.
– Build mappings – Relate business objects to physical structures in sources.
– Configure connectors – For each source define connector for communication. Handles authentication, SQL dialect etc.
– Develop services – Build reusable data services for common query scenarios.
– Test and validate – Test connectivity, data retrieval, joining, performance. Fix issues.
– Deploy – Deploy solution into production environment. Monitor usage and performance.
Benefits of data virtualization
Some of the key benefits driving adoption of data virtualization include:
Faster time to value
– Eliminates time needed to physically move data
– New data sources can be added without delays
– Users get quick access to integrated results
Agility
– Easy to adapt to changes in source systems
– Business users can get new views without IT project delays
– Faster to add new sources and applications
Single source of truth
– Consistent results from centralized data services
– Reduces errors from separate copies of data
– Common business rules applied across sources
Cost efficiency
– Avoids overhead of data replication and ETL processing
– Leverages existing infrastructure investments
– Consolidates rather than copies data
Flexibility
– Logical abstraction layer insulates users from sources
– Simpler to change underlying sources
– Reuse data services for multiple needs
Use cases for data virtualization
Common use cases where data virtualization delivers high business value:
Data warehousing and BI
– Simplify access to distributed enterprise data for analysis
– Avoid delays from batch ETL process
– Leverage data virtualization as the semantic hub of a modern data warehouse
Application integration
– Quickly connect applications to new data sources
– Expose reusable data services for integration
– Simplify integrating SaaS applications
Master data management
– Provide unified views of critical master data like customer, product, supplier
– Deliver MDM across relational and big data sources
– Consolidate data without persisting duplicates
Data migration
– Virtualize access to source and target during migration to simplify cutover
– Avoid direct copies between source and target data stores
– Minimize business disruption by enabling migration in phases
Cloud adoption
– Virtualize data across on-prem and cloud sources
– Simplify integration as applications move to the cloud
– Control access to data sources without copying to cloud
Comparing data virtualization vs. ETL
Data virtualization and traditional ETL take very different approaches:
ETL (extract, transform, load)
– Physically copies data to target database or warehouse
– Batch window for periodic data loads
– Brittle pipelines make change difficult
– Duplicates all integrated data
– Lengthy data movement operations
Data Virtualization
– Data remains in sources, accessed on demand
– Real-time access with no waits for batches
– Abstracted data services simplify change
– Avoids duplicates using logical integration
– Sources queried in place so less data movement
Data virtualization platforms
Leading data virtualization platforms include:
– Denodo – The data virtualization pioneer. Provides full capabilities.
– Oracle Data Services – Part of Oracle’s cloud data integration offering.
– Azure Data Virtualization – Microsoft’s Azure cloud based solution.
– IBM Cloud Pak for Data – Data virtualization is part of this broader offering.
– Stone Bond Enterprise Enabler – Virtualization plus master data management.
– Red Hat JBoss Data Virtualization – Open source based data virtualization.
Data virtualization best practices
Best practices for getting the most out of data virtualization:
– Start with high value use cases – Target efforts where virtualization adds clearest business value.
– Plan for growth – Architect solution for expansion in users, data volumes, sources etc.
– Build in governance – Include data quality, security, metadata management from the start.
– Make it sustainable – Standardize services and metadata so changes are quick and reliable.
– Hide complexity – Present users with business focused views that abstract technical complexity.
– Active tuning – Monitor and tune queries, caching, and sources for optimal performance.
– Data abstraction – Insulate users from changes in physical sources using abstraction layer.
– Shared semantics – Reuse common business vocabularies and rules across solutions.
When to consider data virtualization
Scenarios where data virtualization may be the right choice:
– Need to deliver quick access to integrated data from disparate sources.
– Require flexibility to change underlying sources with minimal disruption to users.
– Looking to consolidate data and retire redundant copies.
– Seeking to enable self-service access to data without always involving IT.
– Need to accelerate delivery of analytics from enterprise data.
– Have master data scattered across systems and want to unify it.
– Any process involving frequent movement of large data volumes.
Limitations and challenges of data virtualization
While data virtualization delivers many benefits, it also has some limitations:
Query performance
– Joining disparate data at runtime can sometimes result in slower queries compared to persisted databases. Requires query optimization.
Unavailable sources
– Virtualized queries may fail if a source system is offline. Less control than a persisted copy.
Transaction integrity
– Not well suited for transactional systems requiring strong data consistency.
Security
– Can make it easier for users to access data from sources they are not authorized for.
Cultural resistance
– Some fear lack of control vs. copying data to a warehouse they own.
Skill gaps
– Requires analytics and integration experts used to virtualized approaches.
Vendor maturity
– Market still maturing. Key vendors provide extensive capabilities but some gaps remain.
The future of data virtualization
Data virtualization is becoming a foundation of modern data management. Key trends include:
– Increasing cloud adoption – Cloud based data virtualization aligns well with distributed data.
– Scaling to big data – Applying more to non-relational data sources like Hadoop.
– Expanding self-service – Empowering more users with self-service access to data.
– Embedded BI – Integrating virtualization into BI and analytics platforms.
– Master data focus – Centralizing master data across sources virtually.
– Meshing with ETL – Using virtualization for some needs and ETL for others based on each approach’s strengths.
Conclusion
Data virtualization delivers simplified data access in a complex, hybrid environment. It removes many of the risks, costs and inflexibilities of traditional ETL based integration. Leading organizations are embracing virtualization as a critical data management capability. For many use cases it provides faster time to value, greater agility and lower costs compared to physical data consolidation. As the landscape grows in distributed data sources, virtualization will become even more relevant. Any organization struggling with accessing and delivering integrated data should strongly consider implementing a data virtualization solution.
| Data Virtualization | ETL |
|---|---|
| Abstracts physical sources | Requires knowledge of sources |
| Queries data in real-time | Batch window for updates |
| Joins data across sources | Persists copied data |
