RAID stands for “Redundant Array of Independent Disks.” It is a technology that combines multiple disk drive components into a logical unit for the purposes of data redundancy and performance improvement.
There are several standard RAID levels that each have their own benefits. RAID 0 involves disk striping to split data across multiple drives but does not provide redundancy. RAID 1 involves mirroring two drives to provide redundancy. RAID 5 provides redundant data storage using parity information spread across multiple disks along with data striping.
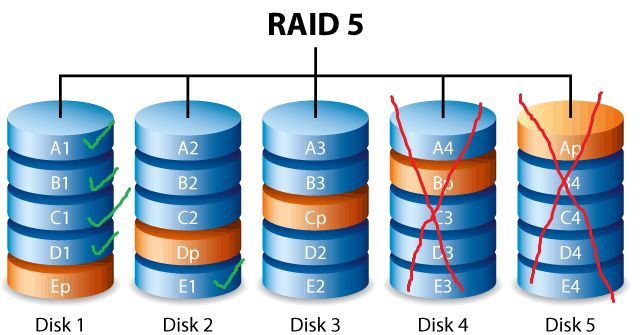
RAID 5 specifically distributes parity information and user data across a minimum of three disks. If one disk fails, the parity information can be used to reconstruct the data that was on the failed drive. This provides fault tolerance and allows continued access to data in the face of disk failures.
RAID 5 Striping
RAID 5 uses distributed parity striping to stripe data across multiple disks. This means the data is divided into blocks and striped across the disks in the array, similar to RAID 0. However, unlike RAID 0, RAID 5 also reserves space on each disk to store parity information that can be used to reconstruct data if a disk fails.
The parity information is calculated by performing an XOR operation across the corresponding data blocks on each disk. For example, if the data blocks on disks 1, 2 and 3 are A1, B1 and C1 respectively, the parity block P1 = A1 XOR B1 XOR C1. This parity block P1 is then stored on disk 4.
The next set of data blocks A2, B2 and C2 are striped across disks 2, 3 and 4, and the parity P2 is stored on disk 1. This alternating pattern continues for the entire RAID 5 array, distributing parity evenly across all disks.
By distributing parity across all the disks, RAID 5 avoids the parity disk bottleneck that exists in RAID 4. This also means that when a disk fails, the workload of recalculating parity and rebuilding the lost data is shared across all the remaining disks.
Sources:
https://sort.veritas.com/public/documents/sfha/6.0/linux/productguides/html/sfcfs_admin/ch04s03s09.htm
https://www.fusiondatarecovery.com/page/raid-5
RAID 5 Parity
RAID 5 uses distributed parity to provide redundancy and fault tolerance while maximizing storage capacity (Rickard Nobel, 2011). Parity allows the system to reconstruct data in the event of a single disk failure (Technote, 2022).
Parity is calculated using XOR arithmetic across the data strips. The parity strip is written across all the drives and not stored on any single disk. For example in a 3-drive RAID 5 array, Disk 1 contains Strip 1, Disk 2 contains Strip 2, and Disk 3 contains the Parity strip calculated from Strip 1 and Strip 2. On the next stripe, the Parity may be on Disk 1 while Strip 2 is on Disk 2 and Strip 3 is on Disk 3, distributing the Parity across all disks (Rickard Nobel, 2011).
If a single drive fails, the parity strips on the surviving drives can be used to reconstruct the lost data. The XOR operation is reversible, so the parity strip can be XOR’d with the surviving data strips to calculate the missing data (Technote, 2022). This is how RAID 5 can recover from a single disk failure.
Why 3 Disks Minimum
RAID 5 requires a minimum of 3 disks due to how data and parity information are distributed across the disks. Specifically, RAID 5 uses block-level striping with distributed parity (Source: https://drivesaversdatarecovery.com/what-are-the-raid-5-requirements/).
This means that data is split up into blocks and striped across all the disks. Parity information is also calculated and written across the disks. The parity blocks allow for recovery of data if one of the disks fails (Source: https://en12057296.ask-invest.online/).
With only 2 disks, there is no room for distributed parity information. All the disk space would be taken up by striped data blocks. Therefore, a minimum of 3 disks is required in RAID 5 – two for striped data blocks and one for distributed parity blocks. The parity blocks are rotated across different disks to avoid overloading any single disk.
In summary, RAID 5 requires a minimum of 3 disks in order to have enough disks for striped data blocks as well as distributed parity blocks. This provides fault tolerance through the parity while also improving performance through striping.
Disk Failure Tolerance
One of the key benefits of RAID 5 is its ability to withstand a single disk failure without losing data. This is achieved through the use of parity information that is distributed across all the disks in the RAID set.
Parity allows the RAID controller to reconstruct data in the event of a disk failure. If one disk fails, the controller uses the parity information from the remaining disks to calculate the missing data from the failed disk. This allows the RAID set to continue operating normally despite the failed disk.
Once the failed disk has been replaced, the controller automatically rebuilds the data on the new disk using the parity information. This rebuild process returns the RAID set back to full redundancy. Overall, the distributed parity provides fault tolerance for a single disk failure in RAID 5.
However, RAID 5 does not provide protection against a second disk failure. If a second disk fails before the first failed disk has been rebuilt, data loss will occur. For this reason, RAID 5 requires a minimum of three disks to provide fault tolerance.
In summary, the parity and striping in RAID 5 allows it to withstand a single disk failure while avoiding data loss. This fault tolerance is a key reason why RAID 5 is a popular choice for redundancy in storage systems.
Rebuilding After Failure
One of the key benefits of RAID 5 is its ability to rebuild the array after a single disk failure. Since RAID 5 uses distributed parity, the data from the failed disk can be recreated from the remaining disks. Here is how the rebuild process works:
When a disk in the RAID 5 array fails, the RAID controller detects the disk failure through regular patrol reads. At this point, the disk is marked as failed but the array remains operational using the parity data spread across the remaining disks.
The controller begins rebuilding the lost data onto a replacement disk that is inserted into the array. Using XOR parity calculations, the controller recreates the data that was on the failed disk and writes it to the new disk. This rebuild process is performed in the background while the RAID continues to handle read/write operations.
The time required to rebuild the lost data depends on the size of the disks and load on the array. For a 1TB disk, the rebuild could take several hours. During the rebuild, the array is vulnerable to a second disk failure, which would result in data loss.
Once the rebuild finishes successfully, the RAID 5 array is restored to full redundancy. The new disk seamlessly takes the place of the failed disk like nothing happened. This rebuild capability allows RAID 5 to withstand a single disk failure without any data loss.
(Source: https://recoverit.wondershare.com/windows-tips/rebuild-raid-5.html)
Performance Impact
RAID 5 offers a balance of performance and storage efficiency compared to RAID 0 and RAID 1. Whereas RAID 0 offers the highest performance by striping data across multiple disks with no parity, it does not provide any fault tolerance. On the other hand, RAID 1 provides fault tolerance through disk mirroring but cuts storage capacity in half. RAID 5 aims for a middle ground by striping data across disks like RAID 0 but also dedicating disk capacity for parity information to enable single disk failure recovery like RAID 1.
For read operations, RAID 5 can offer similar or slightly better performance compared to RAID 0 depending on whether the workload is seek-time or transfer-rate bound. This is because the parity disk can be used to satisfy some read requests in parallel. However, RAID 5 exhibits lower performance for write operations due to the overhead of parity calculation on writes [1]. Overall, benchmarks show RAID 5 achieving 66-75% the write performance of RAID 0 with 3 disks. Compared to RAID 1, RAID 5 provides significantly higher throughput for both reads and writes by distributing I/O across multiple disks instead of duplicating all operations like mirroring.
In summary, RAID 5 delivers higher performance than RAID 1 with better storage efficiency, but lower performance than RAID 0 with the benefit of fault tolerance. It is a practical solution when high performance and high availability are needed but cost limitations prevent using RAID 0+1.
Ideal Use Cases
RAID 5 offers a good balance of performance, storage efficiency, and redundancy for many applications. Some ideal use cases and environments for RAID 5 include:
RAID 5 is well-suited for file and application servers that need to maximize storage capacity while still providing redundancy against a single disk failure. The ability to continue operating if one disk fails makes it a popular choice for critical business data and applications [1].
Because it does not require as many disks as RAID 6 or RAID 10, RAID 5 can provide an economical solution for smaller servers and workstations that need fault tolerance. Many small businesses use RAID 5 to protect important data on their file servers.
With its striping performance advantages, RAID 5 works well for databases and other applications that benefit from improved read speeds across multiple disks. The parity calculation does incur a write penalty, so extremely write-intensive uses like video editing may prefer RAID 10 [2].
For network attached storage devices (NAS) and other secondary storage, RAID 5 offers a good combination of usable space and redundancy for home media servers, backups, archiving, and similar use cases.
Overall, RAID 5 hits a sweet spot for storage environments that need to maximize drive space without compromising too heavily on performance or redundancy.
[1] https://www.techtarget.com/searchstorage/definition/RAID-5-redundant-array-of-independent-disks
[2] https://softraid.com/raid_uses/
Alternatives to RAID 5
While RAID 5 is a popular RAID level, it has some drawbacks that may make other RAID levels or alternatives more appealing in certain situations. Some of the main alternatives to consider include:
RAID 6 – Like RAID 5, RAID 6 provides parity-based redundancy for failure tolerance. However, RAID 6 utilizes a second distributed parity block to protect against the failure of two drives simultaneously. This provides better protection than RAID 5, but at the expense of reduced write performance.
RAID 10 – RAID 10 is a nested or hybrid RAID level that combines distributed data blocks (striping) with mirrored pairs. This provides faster performance than RAID 5 or 6 along with the ability to survive multiple drive failures as long as no more than one drive fails per mirrored pair.
JBOD – Just a Bunch of Disks (JBOD) involves connecting multiple drives as separate devices. This provides flexibility but no redundancy. Software-based redundancy like distributed file systems can be used on top of JBOD.
Erasure coding – Advanced erasure coding schemes like Reed-Solomon codes can provide distributed parity-based redundancy like RAID 5 but require fewer parity drives. This comes at the cost of significant computational overhead however.
Backups – Maintaining recent backups on separate media provides redundancy against drive failures without the rigid structure of RAID. Backups should be an essential part of any storage strategy.
Conclusion
In summary, RAID 5 requires a minimum of three disks in order to provide data striping with distributed parity for redundancy. By striping data across multiple disks and storing parity information distributed across all disks, RAID 5 is able to withstand the failure of one disk without data loss. The tradeoffs are reduced storage efficiency and write performance compared to a single disk, but improved redundancy and read performance. RAID 5 is best suited for applications that require high read performance and can tolerate slower writes, such as data warehousing, file and application servers. While RAID 5 does provide redundancy, other RAID levels like 6 and 10 offer higher fault tolerance and performance for mission critical systems.
